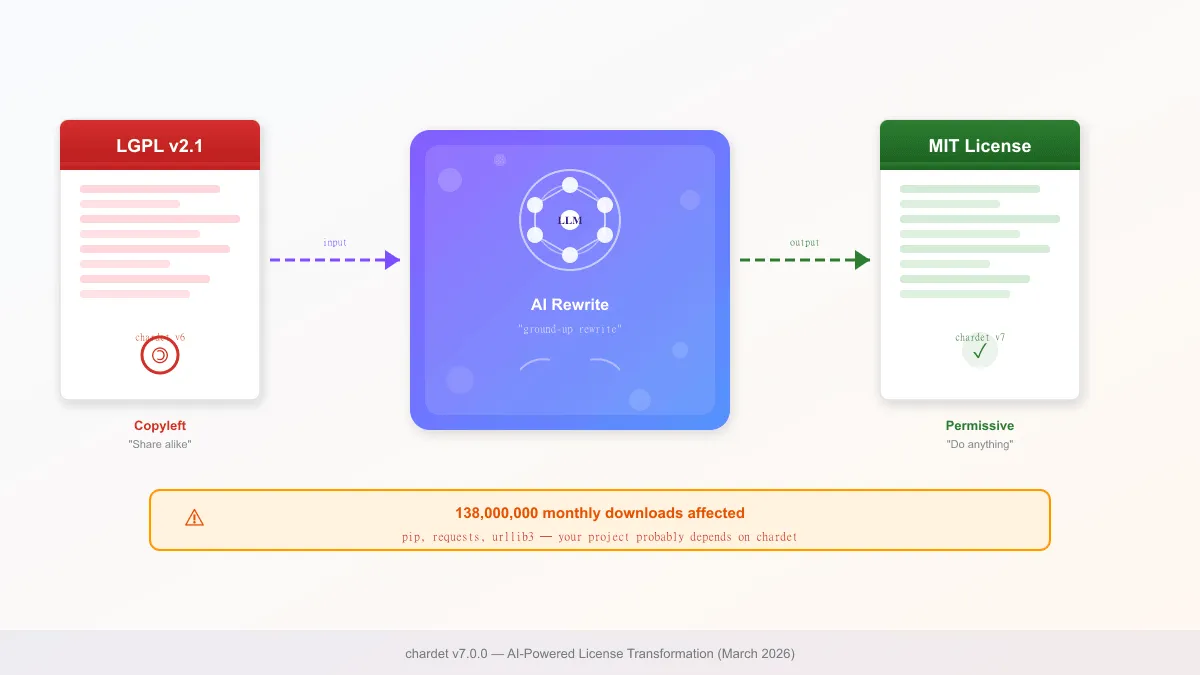
2026년 3월 5일, Python 생태계에 조용한 폭탄이 터졌다. 월간 1억 3,800만 다운로드를 기록하는 문자 인코딩 감지 라이브러리 chardet가 v7.0.0으로 업데이트됐다. 릴리즈 노트에는 “ground-up rewrite, 43배 성능 향상, MIT 라이선스로 전환”이라고 적혀 있었다.
여기까지만 보면 대단한 업그레이드다. 문제는 그 “ground-up rewrite”의 실체가 기존 LGPL 코드를 Claude AI에 넣고 돌린 결과물이라는 사실이 밝혀지면서 시작됐다. 오픈소스 커뮤니티는 즉각 반발했고, GitHub Issue는 48시간 만에 수백 개의 댓글로 폭발했다.
이건 단순한 라이브러리 업데이트 논란이 아니다. AI를 이용한 오픈소스 라이선스 세탁이 가능한가? 이 질문에 대한 첫 번째 대규모 실전 테스트다.
chardet는 뭐고, 왜 이렇게 된 건가
chardet는 Python에서 텍스트 파일의 문자 인코딩을 자동 감지하는 라이브러리다. requests, pip, urllib3 등 Python 핵심 패키지들이 의존하고 있어서, 사실상 Python을 쓰는 사람이라면 자기도 모르게 쓰고 있을 가능성이 높다. PyPI 기준 월 1.3억 다운로드는 상위 0.01%에 해당하는 수치다.
원래 chardet는 Mozilla의 universalchardet C++ 코드를 Python으로 포팅한 것이었고, LGPL(GNU Lesser General Public License) 라이선스로 배포되고 있었다. LGPL은 “이 코드를 쓰거나 수정하면 같은 LGPL로 공개해야 한다”는 카피레프트 조항이 있다.
v7의 메인테이너는 이렇게 주장했다:
“v7은 처음부터 새로 작성된 코드이므로 새로운 저작물이다. 따라서 LGPL에 구속되지 않으며, MIT 라이선스로 배포할 수 있다.”
하지만 “처음부터 새로 작성”의 방법이 문제였다. 기존 LGPL 코드베이스와 테스트 스위트를 Claude AI에 입력하고, “이것과 동일한 기능을 하는 코드를 새로 작성하라”고 지시한 것이다. 결과물은 구조적으로 원본과 유사하되, 변수명과 함수 구조가 달라진 코드였다.
왜 이것이 “라이선스 세탁”인가
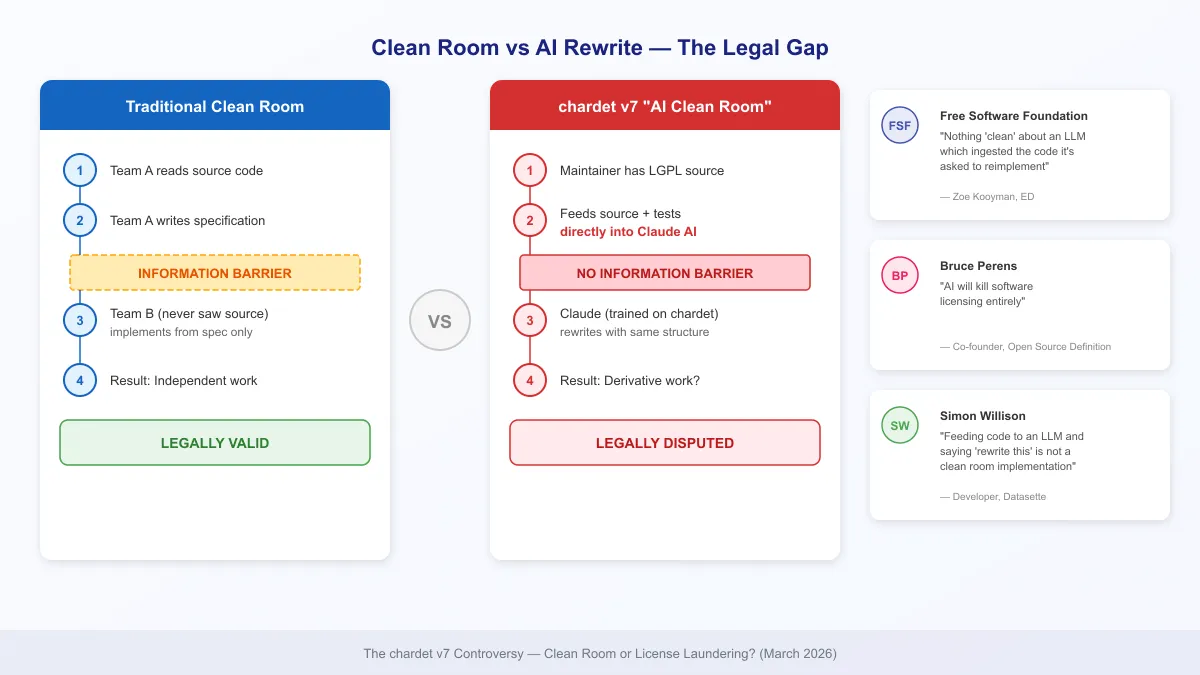
클린룸 역설계(clean room reverse engineering)라는 개념이 있다. 원본 코드를 본 적 없는 팀이 명세서만 보고 새로 구현하면 독립 저작물로 인정받는 방식이다. 이것은 수십 년간 소프트웨어 산업에서 합법적으로 사용되어 온 관행이다.
chardet v7의 메인테이너도 이 논리를 적용하려 했다. “Claude가 새로 작성했으니 클린룸이다”라는 주장이다.
문제는 Claude가 “클린”하지 않다는 것이다.
첫째, Claude는 방대한 오픈소스 코드를 학습 데이터로 사용했다. chardet 자체가 학습 데이터에 포함되어 있을 가능성이 극히 높다. 원본 코드를 “본 적 없는” AI가 아니라, 원본 코드를 이미 “학습한” AI다.
둘째, 메인테이너가 기존 LGPL 코드를 직접 프롬프트에 입력했다. 이것은 클린룸의 핵심 전제 — 원본 코드에 대한 접근 차단 — 을 정면으로 위반한다.
셋째, 테스트 스위트도 함께 입력했다. 테스트 코드 역시 LGPL 저작물이다. AI에게 “이 테스트를 통과하는 코드를 만들어라”고 한 것은 결국 원본의 동작을 복제하라는 지시와 같다.
Simon Willison은 이 사건에 대해 이렇게 정리했다:
“기존 코드를 LLM에 넣고 ‘이것을 다시 작성하라’고 하는 것은 클린룸 구현이 아니다. 이것은 세탁이다.”
업계 반응 — “오픈소스의 사회적 계약이 무너지고 있다”
이 사건에 대한 반응은 빠르고 강렬했다.
자유 소프트웨어 재단(FSF) — Zoë Kooyman 사무총장은 “AI가 코드를 ‘소화’했다고 해서 원본 저작권이 사라지는 것이 아니다”라고 못 박았다. LLM이 학습 데이터에서 코드를 흡수한 이상, 그 출력물이 “클린”하다고 볼 수 없다는 입장이다.
Bruce Perens (오픈소스 정의 공동 창시자) — “AI가 소프트웨어 라이선스를 죽이게 될 것”이라며 더 근본적인 경고를 했다. The Register와의 인터뷰에서 그는 chardet 사건이 빙산의 일각이며, AI를 이용한 라이선스 우회가 산업 전체로 확산될 것이라고 예측했다.
GitHub Issue 폭발 — chardet 레포지토리에는 #327 “No right to relicense this project”과 #331 “v7.0.0 presents unacceptable legal risk to users” 등의 이슈가 올라왔다. #331에서는 v7을 의존성에 포함한 모든 프로젝트가 법적 리스크를 안게 된다고 경고하고 있다.
미국 대법원 판결의 타이밍 — 공교롭게도 2026년 3월 2일, 미국 대법원은 AI 생성물의 저작권 등록 거부에 대한 항소를 기각했다. “인간 저작자 요건”이 사실상 확정된 것이다. 이 판결의 논리를 따르면, Claude가 작성한 chardet v7 코드는 저작권 보호를 받지 못할 수도 있다. 그렇다면 이 코드에 MIT 라이선스를 부여하는 것 자체가 법적으로 유효한가?
개발자가 지금 당장 확인해야 할 것
이 사건이 남의 일이 아닌 이유는 간단하다. chardet는 거의 모든 Python 프로젝트의 의존성 트리에 들어있다. pip install로 뭔가를 설치해 본 적이 있다면, 높은 확률로 chardet가 이미 깔려 있다.
지금 당장 확인해야 할 체크리스트:
# 1. 내 프로젝트에 chardet가 있는지 확인
pip list | grep chardet
# 2. 버전 확인 (v7이면 주의)
python -c "import chardet; print(chardet.__version__)"
# 3. 의존성 트리에서 chardet를 누가 끌어오는지 확인
pip show chardet
# 4. v6로 고정하는 방법
pip install "chardet<7"
만약 프로덕션 서비스를 운영하고 있고 LGPL 컴플라이언스가 중요한 환경이라면, v7으로의 자동 업그레이드를 차단하는 것이 안전하다. requirements.txt나 pyproject.toml에 버전 상한을 걸어두자.
# pyproject.toml
[project]
dependencies = [
"chardet>=5.0,<7.0",
]
더 넓은 차원에서, 이 사건은 모든 개발자에게 새로운 질문을 던진다:
- 내가 쓰는 라이브러리가 AI로 재작성된 적 있는가? — 앞으로 이런 사례가 늘어날 것이다
- AI가 작성한 코드의 라이선스를 신뢰할 수 있는가? — 아직 법적 프레임워크가 없다
- 의존성 업데이트 시 라이선스 변경을 감시하고 있는가? — 대부분의 CI/CD 파이프라인에는 이 체크가 없다
마치며 — 판도라의 상자는 이미 열렸다
chardet 사태의 본질은 기술적인 것이 아니라 사회적 계약의 붕괴다. 오픈소스는 “내가 코드를 공개하면 다른 사람도 공개한다”는 호혜적 신뢰 위에 작동해왔다. AI가 이 신뢰 구조를 우회할 수 있게 되면, 오픈소스 생태계의 근간이 흔들린다.
Bruce Perens의 경고처럼, 이것은 시작일 뿐이다. chardet가 되든 다른 라이브러리가 되든, “AI로 코드를 다시 쓰면 라이선스를 바꿀 수 있다”는 선례가 굳어지는 순간, 모든 카피레프트 라이선스는 사실상 무력화된다.
법원의 판단이 나오기까지는 시간이 걸릴 것이다. 그 사이에 개발자들이 할 수 있는 것은 명확하다: 의존성을 감시하고, 라이선스 변경을 추적하고, AI 생성 코드의 출처를 검증하는 습관을 들이는 것. 2026년의 개발자에게 pip install은 더 이상 무심코 칠 수 있는 명령어가 아니다.