AI 코딩을 천천히 쓰는 법이 갑자기 더 현실적으로 보이기 시작했다. 요즘 분위기는 대체로 반대였다. 더 빨리 만들고, 더 많은 diff를 뽑고, 더 많은 PR을 올리는 쪽으로 숫자가 달렸다. 그런데 2026년 5월 26일 아침에 GeekNews, Hacker News, Lobsters에서 동시에 튄 글은 정반대 이야기를 했다. AI를 써서 더 좋은 코드를, 더 천천히 쓰자는 얘기다.
처음엔 제목만 보고 약간 뻔하다고 생각했다. “품질이 중요하다”는 말은 누구나 한다. 근데 Nolan Lawson의 글을 읽어보면 핵심이 조금 다르다. AI가 코드를 빨리 쓰게 하는 도구라는 전제를 잠깐 내려놓고, PR 리뷰에서 결함을 찾고 우선순위를 정하는 도구로 쓰자는 쪽에 가깝다. 나는 이 관점이 꽤 마음에 들었다. 특히 요즘처럼 AI가 만든 코드의 양보다 검증 비용이 더 자주 병목이 되는 팀에서는 더 그렇다.

이전에 AI 코딩 성과 지표를 다루면서도 비슷한 얘기를 했다. 생성량이 늘었다고 팀이 빨라졌다고 말하기 어렵다. 누군가는 그 코드를 읽고, 테스트하고, 되돌리고, 운영 장애 가능성을 상상해야 한다. 그래서 이번 글은 “AI 코딩을 쓰지 말자”가 아니다. 오히려 더 깊게 쓰자는 쪽이다. 다만 빠른 타이핑 기계가 아니라 느린 리뷰 파트너로.
빠른 생성보다 느린 리뷰가 더 뜨거워진 이유
커뮤니티 반응이 말하는 것
이번 주제가 화제성이 높은 이유는 단순히 글쓴이가 유명해서만은 아니다. GeekNews 첫 화면에서 “AI를 사용해 더 나은 코드를 더 천천히 작성하기”가 최상단에 올라왔고, Hacker News 첫 화면에서도 같은 글이 빠르게 토론을 모았다. Lobsters 토론도 꽤 길게 붙었다.
이 조합이 재미있다. 개발자 커뮤니티가 AI 코딩을 완전히 거부하는 것도 아니고, 무조건 환호하는 것도 아니다. 지금 관심사는 “얼마나 빨리 만들었나”에서 “그 결과를 누가 어떤 방식으로 믿을 수 있나”로 옮겨가고 있다.
나는 이 변화가 자연스럽다고 본다. 처음 도구를 만질 때는 속도가 제일 잘 보인다. 빈 파일에 기능이 생기고, 테스트 이름이 채워지고, 낯선 API 호출 예제가 금방 나온다. 그런데 몇 주만 지나도 다른 비용이 보인다. PR이 커지고, 리뷰어가 지치고, 코드가 맞는 것처럼 보이지만 시스템의 오래된 가정과 안 맞는 순간이 나온다. 그때부터 “빨랐다”는 감상이 별 의미가 없어질 때가 있다.
속도 지표의 빈틈
AI 코딩 도구가 만들어내는 가장 위험한 착시는 처리량이다. diff가 많으면 일이 진행된 것처럼 보인다. 이슈가 닫히면 생산성이 오른 것처럼 보인다. 하지만 리뷰 대기열이 밀리고, QA에서 다시 열리고, 운영에서 이상한 edge case가 튀어나오면 앞의 숫자는 별로 위로가 안 된다.
OpenAI의 Datadog Codex 사례를 보면 이 지점이 선명하다. Datadog은 Codex를 단순한 스타일 검사기가 아니라 시스템 수준의 코드 리뷰 보조로 다뤘고, 과거 incident와 연결된 PR을 다시 돌려보며 실제로 어떤 위험을 잡는지 봤다. 내가 여기서 중요하게 본 건 “시간 절약”보다 “사람이 놓치는 연결을 보완한다”는 쪽이다.
이건 AI 리뷰가 사람 리뷰어를 대체한다는 말이 아니다. 오히려 반대다. 사람이 하기 어려운 반복 탐색과 큰 컨텍스트 훑기를 기계가 맡고, 사람은 최종 판단과 설계 책임으로 올라가는 그림에 가깝다. 말은 쉽다. 실제로는 프롬프트, 권한, 테스트, 실패 기준, false positive 처리까지 다 정해야 한다.
AI 코딩 PR 리뷰는 결함 찾기보다 분류가 어렵다
여러 에이전트를 따로 돌리는 이유
Nolan의 글에서 제일 실용적으로 느낀 부분은 여러 도구를 따로 돌린 뒤 결과를 합치는 방식이었다. Claude 하위 에이전트, Codex, Cursor Bugbot 같은 리뷰어를 각각 돌리고, 마지막에 사람이 결과를 합쳐 critical, high, medium, low로 나눈다. 핵심은 한 모델에게 “다 알아서 해줘”라고 맡기지 않는 것이다.
이 접근은 꽤 개발자답다. 우리가 테스트도 하나만 믿지 않는 것과 비슷하다. 타입 체크, 단위 테스트, 통합 테스트, 린트, 보안 스캔이 서로 다른 실패를 잡는다. AI 리뷰도 마찬가지로 보면 된다. 한 에이전트는 API contract를 잘 보고, 다른 에이전트는 race condition을 더 잘 의심하고, 또 다른 에이전트는 테스트 누락을 잘 잡을 수 있다.
근데 이 방식의 진짜 장점은 결함을 많이 찾는 데서 끝나지 않는다. 서로 다른 모델이 같은 문제를 독립적으로 지적하면 신호가 강해진다. 반대로 한 모델만 말한 애매한 지적은 사람이 더 차갑게 볼 수 있다. AI가 낸 리뷰를 또 다른 AI에게 합치게 할 수도 있지만, 나는 여기서 사람의 손을 남겨두는 편이 낫다고 본다. 최종 merge 책임은 결국 사람이 진다.
사람의 일은 마지막 판단으로 이동한다
Anthropic의 Mythos Preview 분석과 Project Glasswing 업데이트를 같이 보면, 요즘 모델이 취약점 탐색에서 생각보다 강한 건 맞다. 특히 여러 에이전트를 병렬로 돌리고, 찾은 내용을 다시 검증하고, 보고서로 정리하는 흐름은 이제 연구 데모에만 머물지 않는다.
하지만 여기서 바로 “그러면 AI가 보안 리뷰를 끝냈다”로 가면 위험하다. Anthropic도 triage와 disclosure 같은 절차를 계속 강조한다. OpenAI의 Datadog 사례도 Codex가 발견한 내용을 실제 incident 맥락에서 사람이 확인했다. 결국 어려운 건 버그 후보를 찾는 게 아니라, 이게 정말 지금 고쳐야 할 문제인지 판단하는 일이다.
나는 이 지점에서 AI 코딩 도구의 역할을 조금 더 좁게 잡는 게 좋다고 본다. “코드 작성자”보다 “의심을 잘 던지는 리뷰어”로 쓰는 것이다. 그러면 기대치가 바뀐다. AI가 완벽한 patch를 내야 하는 게 아니라, 사람이 놓칠 수 있는 질문을 많이 던지면 된다. 그 질문 중 진짜를 골라내는 일은 여전히 개발팀의 몫이다.
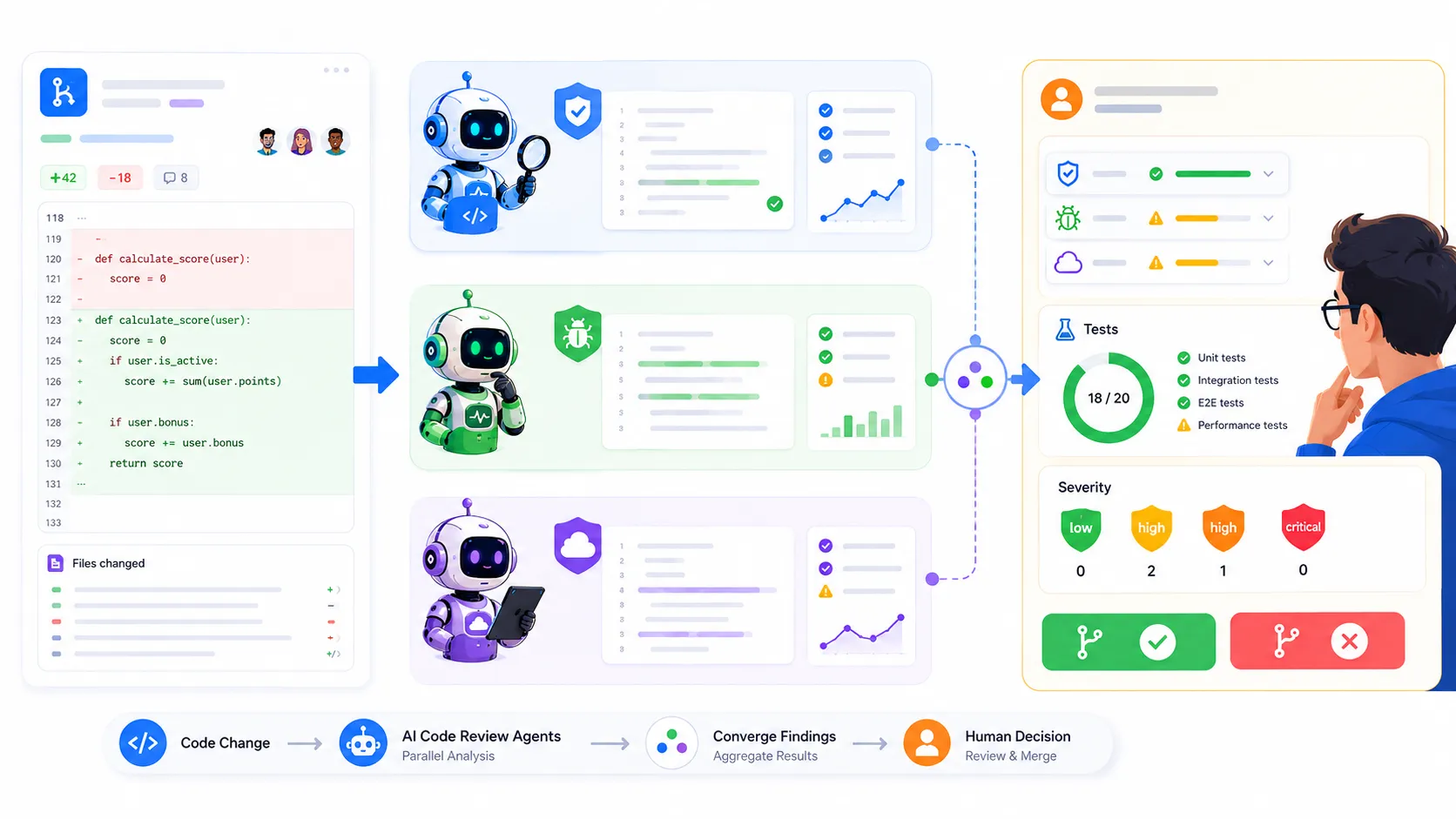
팀에서 바로 써볼 수 있는 느린 AI 리뷰 루틴
리뷰어를 세 개로 나눈다
내가 팀에서 이 흐름을 적용한다면 처음부터 거창한 플랫폼을 만들지는 않을 것 같다. PR 하나를 대상으로 역할을 나누고, 각 역할이 같은 diff를 다른 관점으로 보게 하는 정도로 시작한다.
예를 들면 이렇게 간단히 쪼갤 수 있다.
- correctness 리뷰어: 요구사항과 실제 동작이 맞는지 본다.
- regression 리뷰어: 기존 사용자 흐름과 테스트가 깨지는지 본다.
- operations 리뷰어: 로그, 성능, 배포, 롤백, 권한 문제가 있는지 본다.
중요한 건 각 리뷰어에게 같은 지시를 복붙하지 않는 것이다. 역할이 다르면 보는 실패도 달라야 한다. correctness 리뷰어에게 “성능도 봐줘”라고 던지고, operations 리뷰어에게 “테스트도 봐줘”라고 던지는 순간 신호가 흐려진다. 사람 리뷰어도 그렇다. 모든 걸 다 보라는 리뷰는 결국 아무것도 제대로 못 본다.
결과를 합치기 전에 컨텍스트를 섞지 않는다
여러 에이전트를 쓸 때 내가 제일 조심할 부분은 선입견이다. 첫 번째 모델이 “이거 위험하다”고 말하면 두 번째 모델에게 그 결과를 보여주고 싶어진다. 하지만 그러면 독립 검토가 아니다. 앞 모델의 프레임을 뒤 모델이 따라갈 수 있다.
그래서 느린 AI 리뷰 루틴은 약간 번거로워야 한다. 먼저 따로 돌리고, 결과를 모은 다음, 마지막에 사람이 묶는다. 대충 이런 식이다.
PR 리뷰 요청:
1. diff와 관련 파일을 읽는다.
2. 네 역할은 regression 리뷰어다.
3. 새 기능 설명보다 기존 동작이 깨질 가능성을 우선 본다.
4. 지적은 critical/high/medium/low로 나눈다.
5. 각 지적마다 재현 방법이나 확인 테스트를 붙인다.
6. 확실하지 않은 추측은 "확인 필요"로 표시한다.
이 프롬프트가 마법이라는 뜻은 아니다. 오히려 반대다. 이런 지시는 아주 평범해야 한다. 팀이 이미 좋은 리뷰어에게 기대하던 행동을 그대로 적는 게 낫다. 모델을 속이거나 멋진 프롬프트를 만들 필요가 없다. 좋은 리뷰 기준을 명시적으로 적는 일이 더 중요하다.
수정보다 질문을 먼저 받는다
AI 코딩 도구를 쓰다 보면 바로 수정시키고 싶어진다. “이거 고쳐”는 너무 편하다. 그런데 PR 리뷰에서는 잠깐 참는 편이 낫다. 먼저 질문과 위험 목록을 받고, 그 다음에 수정할 항목을 고르는 게 좋다.
나는 여기서 개발자의 감각이 중요하다고 본다. AI가 medium으로 분류한 문제가 실제로는 운영에서 critical일 수 있고, high라고 한 지적이 제품 요구사항을 모르는 헛소리일 수도 있다. 그래서 바로 patch를 받는 흐름은 위험하다. 처음에는 “무엇이 의심스러운가”만 받고, 수정은 사람이 골라서 진행하는 편이 더 안전하다.
생산성 숫자보다 남는 질문
느린 AI 코딩은 도구 낭비가 아니다
처음엔 “AI를 써서 더 천천히 한다”는 말이 모순처럼 들린다. 돈 내고 쓰는 도구인데 왜 느리게 쓰나 싶다. 하지만 실제 개발에서는 느린 검증이 빠른 복구보다 싸게 먹힐 때가 많다. 특히 결제, 인증, 데이터 마이그레이션, 인프라, 보안처럼 한 번 삐끗하면 뒤처리가 큰 영역에서는 더 그렇다.
AI 시대의 코드 리뷰를 다시 생각하는 arXiv 논문도 비슷한 문제를 짚는다. AI coding assistant가 코드 생산량을 늘리면서 리뷰 부담이 커지고, 단편적인 코멘트 도구가 아니라 PR 생성부터 회고까지 이어지는 agentic review workflow가 필요하다는 흐름이다. 논문체라 조금 딱딱하지만 문제의식은 현실적이다.
내 기준으로는 이게 지금 AI 코딩의 다음 단계다. 초안 생성은 이미 충분히 강하다. 이제 차이는 검증 루틴에서 난다. 어떤 팀은 AI가 만든 코드를 더 빨리 merge하는 데 쓸 것이고, 어떤 팀은 AI를 써서 merge를 더 까다롭게 만들 것이다. 나는 후자가 오래 간다고 본다.
좋은 리뷰어를 복제하는 게 아니라 리뷰 압력을 분산한다
AI 코드 리뷰를 말하면 자주 나오는 질문이 있다. “우리 팀 최고 시니어만큼 잘 보나?” 이 질문은 반쯤 맞고 반쯤 빗나갔다. 최고 시니어 한 명을 복제하는 건 어렵다. 도메인 기억, 제품 감각, 장애 경험, 정치적 판단까지 들어가기 때문이다.
대신 AI는 리뷰 압력을 분산할 수 있다. 반복적인 edge case 탐색, 빠뜨린 테스트 후보, API 변경 영향, 문서와 코드의 불일치 같은 건 꽤 잘 던진다. 그 덕분에 사람 리뷰어는 처음부터 모든 걸 손으로 뒤지는 대신, 더 진한 문제에 집중할 수 있다.
물론 이 흐름도 공짜는 아니다. AI 리뷰가 남긴 코멘트가 너무 많으면 그 자체가 noise가 된다. 그래서 팀은 “AI가 지적했으니 고친다”가 아니라 “AI가 지적한 것 중 우리가 책임질 항목을 고른다”는 태도를 가져야 한다. 이 차이가 작아 보이지만 실제로는 크다.
마치며
AI 코딩을 천천히 쓰는 법은 반AI 선언이 아니다. 오히려 AI를 개발팀 안에 더 깊게 넣는 방식이다. 다만 중심이 생성 속도에서 검증 품질로 옮겨간다. 나는 이 변화가 꽤 건강하다고 본다.
지금까지는 “AI가 코드를 얼마나 빨리 만들었나”가 데모에서 가장 잘 팔렸다. 앞으로는 “AI가 사람이 놓칠 위험을 얼마나 검증 가능한 형태로 가져왔나”가 더 중요해질 가능성이 크다. PR 리뷰는 그 변화를 제일 먼저 체감할 곳이다. merge 버튼 앞에서 필요한 건 더 많은 코드가 아니라 더 좋은 의심이니까.