OpenAI가 2026년 4월 22일에 Privacy Filter를 공개한 뒤 분위기가 묘하게 달라졌다. 신모델이 나왔다보다, 드디어 개인정보 지우는 전용 모델을 아예 열어버렸다는 느낌이 더 세다. HN 첫 화면까지 올라왔고 Hugging Face 공개 페이지도 바로 붙었다. 이런 건 보통 며칠 지나면 식는데, 이번 건은 로그 정제, 학습 데이터 전처리, 코드베이스 비밀값 스캔까지 바로 실무 얘기로 넘어간다.
나도 처음엔 그냥 또 하나의 안전성 데모겠지 싶었다. 근데 공식 글이 꽤 노골적이다. 작고 빠르고 로컬에서 돌릴 수 있고, training indexing logging review pipeline에 바로 넣으라고 한다. 이런 문장은 제품 소개보다 운영팀 호출장에 더 가깝다. 어제 쓴 MCP 취약점 공포에 다들 흔들리는 이유랑도 연결된다. 이제 다들 에이전트를 어디에 붙일지만 보는 게 아니라, 붙이기 전에 뭘 지우고 뭘 막아야 하는지부터 다시 세기 시작했다.

갑자기 이게 왜 뜨냐
이번엔 발표 위치가 다르다
OpenAI 공식 릴리스가 제일 먼저 눈에 들어오긴 하는데, 진짜 포인트는 배포 형태다. 그냥 API 옵션 하나 추가한 게 아니다. Apache 2.0으로 풀었고, Hugging Face와 GitHub에 같이 올렸고, 브라우저나 노트북에서도 돌릴 수 있다고 박았다. 즉 “우리 클라우드에 보내서 알아서 쓰세요”가 아니라 “너희 환경 안에서 직접 돌려” 쪽이다. 프라이버시 얘기할 때 이 차이가 꽤 크다.
개발자 입장에서는 적용 지점이 바로 보인다
공식 설명을 보면 이 모델은 텍스트에서 PII를 찾아서 가리는 데 집중한다. 이름, 주소, 이메일, 전화번호, URL, 날짜, 계정번호, 그리고 secret까지 8개 범주다. 여기서 secret이 들어간 순간부터 얘기가 달라진다. 갑자기 이건 개인정보 모델이 아니라 로그 정제기이자 비밀값 스캐너처럼 보이기 시작한다. 프롬프트 로그, 에이전트 실행 기록, 지원 티켓 덤프, RAG 인덱싱 전에 한 번 훑는 용도가 바로 떠오른다.
숫자는 생각보다 세다
작게 보이는데 길게 먹는다
공식 릴리스 기준으로 Privacy Filter는 총 1.5B 파라미터에 활성 파라미터는 50M이고, 128000 토큰 문맥을 처리한다. 나는 여기서 “아 크다 작다”보다 “한 번에 길게 본다”가 더 중요하다고 봤다. 개인정보 마스킹이 제일 귀찮아지는 순간이 긴 로그를 여러 청크로 쪼개다가 문맥이 끊기는 때라서 그렇다. 작은 모델인데 긴 문맥을 한 번에 훑는다는 조합은 운영 파이프라인 입장에서 꽤 매력적이다.
성능 홍보도 그냥 숫자 놀이는 아니다
OpenAI는 PII Masking 300k에서 F1 96퍼센트, 교정 버전에서는 97.43퍼센트를 말한다. 솔직히 이런 수치는 늘 한 번 의심하고 봐야 한다. 그래도 모델 카드까지 같이 보면 secret 탐지 쪽도 따로 평가했다. CredData 기준 token recall이 0.965까지 나온다. span F1은 더 낮아서 여전히 경계선 문제는 남아 있지만, 적어도 “비밀값도 본다”는 말이 마케팅 문구만은 아니라는 뜻이다.
git clone https://github.com/openai/privacy-filter.git
cd privacy-filter
pip install -e .
opf -f ./sample-log.txt
이 정도면 사내 샌드박스에서 바로 한 번 돌려볼 만하다. 거창한 플랫폼 붙이기 전에, 유출되면 곤란한 텍스트가 얼마나 잡히는지부터 보는 게 낫다.
근데 바로 프로덕션 넣으면 좀 위험하다
이건 컴플라이언스 인증서가 아니다
공식 문서도 이걸 꽤 분명하게 적는다. Privacy Filter는 anonymization 자체도 아니고 compliance 보증도 아니고, high stakes 환경에서는 사람 검토가 여전히 필요하다고 한다. 이 문장을 빼놓고 “로컬 PII 마스킹 끝”처럼 말하면 바로 사고 난다. 법무나 의료, 금융처럼 한 번 틀리면 비용이 큰 영역에선 이걸 단독 필터로 세우면 안 된다.
한국어와 도메인 편차는 따로 봐야 한다
모델 카드의 톤을 보면 주력 언어는 영어다. selected multilingual robustness evaluation은 있지만, 한국어 고객센터 로그나 사내 위키 텍스트 같은 데서 어느 정도까지 안정적으로 잡히는지는 직접 재봐야 한다. 특히 한국 이름, 섞여 있는 영문 계정명, 사내 시스템이 쓰는 이상한 식별자, 프로젝트마다 다른 secret 포맷은 기본값이 자주 빗나간다. 이걸 안 보고 바로 운영에 넣으면 과소 마스킹이나 과잉 마스킹 둘 다 만난다.
어디에 먼저 꽂으면 체감이 오냐
학습 데이터 전처리보다 로그 정제가 먼저다
사람들이 보통 “우리 데이터셋 정제에 써야지”부터 떠올리는데, 나는 오히려 로그 쪽이 먼저라고 본다. 이미 돌아가는 에이전트와 지원 툴에서 하루에도 수천 줄씩 민감 텍스트가 쌓이는데, 거기부터 줄이는 게 바로 체감이 난다. 긴 토큰을 한 번에 보고 로컬에서 돌릴 수 있다는 장점도 이 구간에서 제일 살아난다.
코드 리뷰보다 먼저 실행 기록을 태워보는 게 낫다
secret 탐지가 된다고 해서 곧바로 GitHub Secret Scanning 대체재가 되는 건 아니다. 그래도 에이전트 실행 기록이나 CLI transcript처럼 기존 보안 툴이 잘 안 보는 텍스트 층에는 꽤 유용해 보인다. 나는 여기에 먼저 붙여보고, 그 다음에 프롬프트 저장소나 내부 검색 인덱스로 넓히는 순서가 현실적이라고 본다.
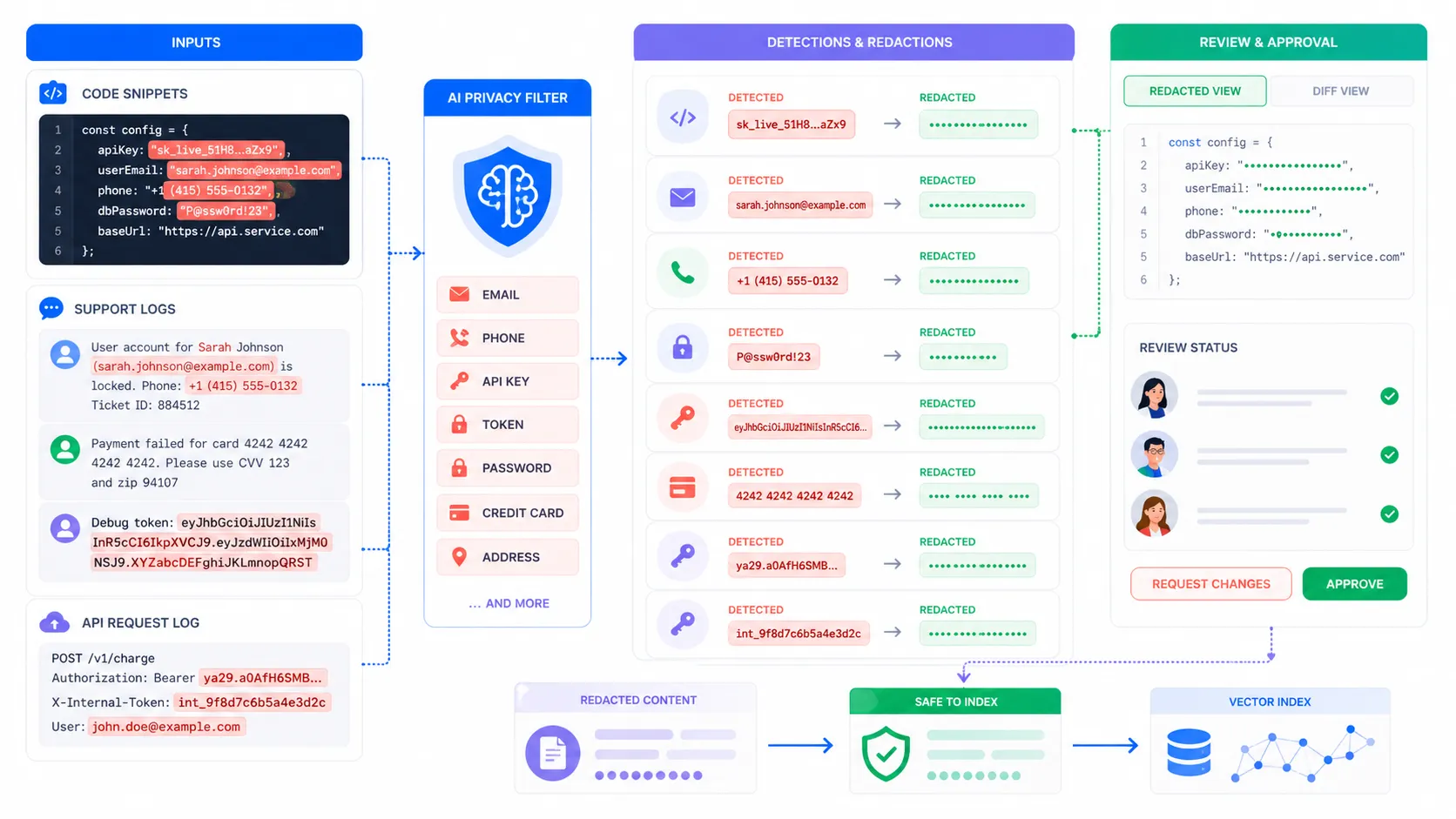
지금 이 주제가 뜨는 이유는 단순히 OpenAI가 또 하나 공개해서가 아니다. 다들 에이전트를 더 길게 돌리기 시작했고, 그 과정에서 민감정보가 어디에 남는지가 진짜 운영 문제가 됐기 때문이다. Privacy Filter는 만능 해결책은 아니지만, 적어도 “모델 쓰기 전에 먼저 지워라”라는 흐름을 한 단계 앞당긴 신호로는 꽤 크게 보인다. 나 같으면 바로 전사 배포부터 안 하고, 사내 로그 한 묶음으로 먼저 사람 기준 정답셋 만든 다음에 오탐과 누락부터 본다. 이건 그 순서만 안 틀리면 꽤 쓸 만해질 가능성이 있다.