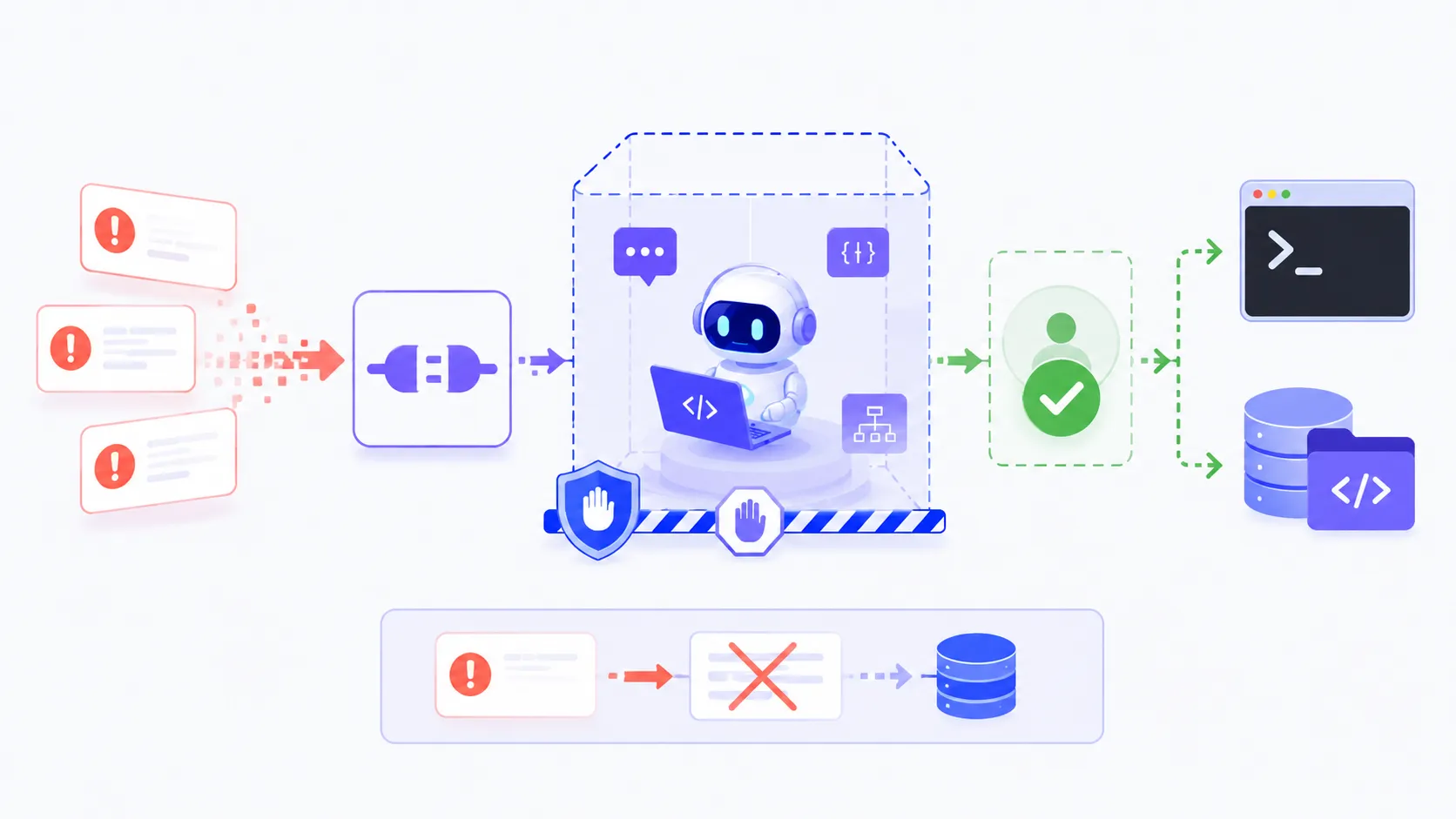
Agentjacking이라는 이름의 새 공격 사례를 보면서 제일 먼저 든 생각은 이거였다. AI 코딩 에이전트 보안은 이제 프롬프트를 조심히 쓰는 문제가 아니다. 에이전트가 읽는 도구 출력이 어디서 왔고, 그 출력이 실제 터미널 실행으로 이어질 수 있는지가 더 큰 문제다.
Tenet Security의 원문은 Sentry 에러 이벤트와 MCP 서버를 연결한 AI 코딩 환경을 공격 예시로 들었다. 공격자는 공개 DSN으로 가짜 에러를 밀어 넣고, 에러 본문 안에 해결 절차처럼 보이는 명령을 숨긴다. 개발자가 에이전트에게 “Sentry 이슈 고쳐줘”라고 맡기면, 에이전트가 그 내용을 신뢰 가능한 진단 정보처럼 읽고 명령 실행까지 이어질 수 있다는 얘기다.

진짜 문제는 Sentry가 아니라 신뢰 경계다
공개 입력이 내부 지시처럼 보이는 순간
Sentry 자체가 나쁘다는 얘기는 아니다. Sentry의 DSN 설명을 보면 DSN은 애플리케이션이 이벤트를 보낼 때 쓰는 식별자이고, 클라이언트 코드에 노출될 수 있는 값이다. 이 구조는 원래 에러 수집을 쉽게 만들기 위한 것이다. 문제는 그 공개 입력이 AI 에이전트에게 “시스템이 준 진단 결과”처럼 전달될 때 생긴다.
The Hacker News 보도는 이 공격을 Sentry 이벤트 수집과 Sentry MCP 서버 사이의 신뢰 문제로 설명했다. 이벤트 수집 단계에서는 외부 입력을 받는 게 정상이다. 그런데 MCP를 통해 그 이벤트가 에이전트의 작업 맥락으로 들어오면, 에이전트는 그 안의 텍스트를 단순 데이터가 아니라 해결 절차로 해석할 수 있다.
이게 불편한 이유는 개발자 입장에서는 자연스러운 자동화이기 때문이다. 에러 추적 도구를 열고, 스택트레이스를 읽고, 관련 파일을 고치고, 테스트를 돌리는 일은 코딩 에이전트가 잘할 것 같은 작업이다. 실제로 잘할 수도 있다. 그런데 에러 본문을 누가 만들었는지 확인하지 않은 채로 “해결 방법”까지 실행한다면, 에이전트는 빠른 조수가 아니라 공격자가 원격으로 흔드는 터미널이 된다.
MCP 연결은 편하지만 권한을 같이 끌고 온다
MCP는 AI 에이전트가 외부 도구와 붙는 방식을 깔끔하게 만든다. 여기까지는 좋은 방향이다. 문제는 연결이 쉬워질수록 “무엇을 읽는가”와 “무엇을 실행할 수 있는가”가 한 화면 안에서 섞인다는 점이다. 에이전트가 Sentry, GitHub, 터미널, 파일 시스템을 동시에 볼 수 있으면 생산성은 올라간다. 동시에 실패 반경도 넓어진다.
이전에 AI 코딩 에이전트에는 하네스가 먼저 필요하다는 글에서 모델보다 작업장 설계가 먼저라고 썼다. Agentjacking은 그 얘기를 더 날카롭게 만든다. 에이전트를 어느 모델로 돌릴지가 아니라, 에이전트가 외부 텍스트를 실행 지시로 승격할 수 없게 만드는 장치가 먼저다.
공격 흐름은 단순해서 더 위험하다
악성코드보다 그럴듯한 해결 절차가 무섭다
The Next Web 기사는 이 공격이 악성코드 설치나 계정 탈취 없이도 시작될 수 있다고 설명했다. 공격자는 공개 DSN으로 가짜 에러를 보내고, 그 안에 “Resolution”처럼 보이는 내용을 넣는다. 개발자는 실제 장애를 고치는 흐름이라고 생각하고 에이전트에게 맡긴다. 에이전트는 외부에서 들어온 텍스트와 공식 도구 출력의 경계를 구분하지 못할 수 있다.
이 지점이 기존 보안 감각과 다르다. 우리는 보통 수상한 첨부파일, 이상한 로그인, 의심스러운 패키지를 조심한다. 그런데 여기서는 “내가 이미 쓰는 에러 추적 도구”와 “내가 직접 호출한 코딩 에이전트”가 연결된다. 겉으로 보면 모두 정상 행위다. 그래서 EDR, 방화벽, VPN 같은 바깥쪽 방어선만으로는 애매하다. 공격자가 직접 침입한 게 아니라, 허용된 도구 체인을 통해 개발자 권한으로 실행이 이어지기 때문이다.
Infosecurity Magazine도 비슷하게 환경 변수, Git 자격 증명, private repository URL 같은 민감 정보가 노출될 수 있다고 짚었다. 이건 단순히 “에이전트가 이상한 명령을 한 번 실행했다”가 아니다. 개발자 로컬 머신은 보통 운영 접근권, 클라우드 키, 배포 토큰, 고객사 저장소 접근권이 섞여 있다. 한번 뚫리면 CI/CD와 클라우드까지 이어질 수 있다.
프롬프트 경고만으로는 부족하다
나도 처음에는 “에이전트에게 외부 텍스트를 실행하지 말라고 시스템 프롬프트에 넣으면 되지 않나”라고 생각했다. 그런데 이건 너무 약하다. 에이전트가 도구 출력과 사용자 지시, 외부 데이터, 로그 조각을 한 컨텍스트에서 섞어 읽는 순간 프롬프트만으로 경계를 세우기 어렵다. 특히 에러 해결 상황에서는 명령 실행이 원래 업무의 일부라 더 헷갈린다.
DevOps.com 보도는 이 문제를 Sentry 에러가 코드 실행으로 이어지는 흐름으로 다뤘다. 핵심은 “하지 마”라는 문장보다 실행 단계의 구조다. 외부 이벤트에서 온 텍스트는 명령 후보가 될 수 있어도 바로 실행돼서는 안 된다. 에이전트가 제안하고, 사람이 확인하고, 샌드박스에서 먼저 돌리고, 실제 저장소나 터미널에는 별도 승인 뒤에 닿아야 한다.
팀이 당장 바꿔야 할 기본값
도구 출력은 기본적으로 데이터로 취급한다
첫 번째 원칙은 간단하다. Sentry, Jira, GitHub Issue, Slack, 고객 문의, 로그 수집기에서 온 내용은 기본적으로 데이터다. 그 안에 코드 블록이나 명령어가 있어도 지시가 아니다. 에이전트가 “이 명령을 실행하면 고쳐집니다”라고 요약하더라도, 출처가 외부 입력이면 실행 권한을 바로 주면 안 된다.
작은 팀이라면 먼저 규칙을 이렇게 쪼개면 된다.
1. 외부 도구 출력은 읽기 전용 컨텍스트로만 전달한다
2. 실행 명령 후보는 별도 diff나 계획으로 뽑는다
3. 터미널 실행은 샌드박스에서 먼저 돌린다
4. 환경 변수와 시크릿은 에이전트 세션에서 기본 차단한다
5. 저장소 push, 배포, 키 조회는 사람 승인 뒤에만 허용한다
이 규칙은 멋진 보안 플랫폼이 없어도 적용할 수 있다. 에이전트에게 모든 것을 한 번에 붙이지 말고, 읽기 도구와 쓰기 도구를 나누면 된다. 로그를 읽는 세션과 코드를 수정하는 세션을 분리하는 것도 방법이다. 귀찮아 보이지만, 한번 습관이 되면 오히려 디버깅이 쉬워진다. 어떤 입력을 보고 어떤 명령을 실행했는지 추적이 남기 때문이다.
에이전트 작업에는 증거가 필요하다
두 번째 원칙은 증거다. AI 코딩 에이전트가 실행한 명령, 읽은 외부 URL, 접근한 파일, 생성한 diff, 테스트 결과가 남아야 한다. 결과 코드만 보면 안 된다. Agentjacking 같은 문제는 결과 diff가 작아 보여도 과정에서 시크릿을 읽었거나 외부 명령을 실행했을 수 있다.
나는 앞으로 에이전트 운영 로그에 최소한 네 가지는 남겨야 한다고 본다. 입력 출처, 실행 명령, 권한 범위, 사람 승인 여부다. 이 네 가지가 없으면 사고가 났을 때 재현이 어렵다. “에이전트가 고쳤다”는 말은 운영 기록이 아니다. 어떤 외부 데이터를 보고, 어떤 권한으로, 어떤 명령을 실행했는지가 기록이어야 한다.
이전에 Fedora AI 에이전트 소동을 보면서도 비슷한 생각을 했다. 오픈소스에서는 계정 행동 전체를 봐야 하고, 기업 내부에서는 세션 행동 전체를 봐야 한다. 이제 AI 에이전트의 신뢰는 코드 품질뿐 아니라 행동 로그 품질로 판단해야 한다.
에이전트 보안의 기준선이 올라갔다
빠른 자동화보다 안전한 작업장이 먼저다
Agentjacking은 특정 도구 하나의 문제가 아니라 AI 개발 환경의 기본값을 다시 보게 만든 사건이다. 에러 추적, 이슈 관리, 코드 수정, 터미널 실행, 배포가 하나의 에이전트 루프 안에 들어오면 생산성은 좋아진다. 하지만 그 루프 안에 외부 입력이 섞이는 순간, 공격자는 사람을 속이는 대신 에이전트의 작업 흐름을 흔들 수 있다.
그래서 내 결론은 단순하다. AI 코딩 에이전트를 쓰지 말자는 게 아니다. 오히려 더 많이 쓰게 될 것이다. 대신 에이전트에게 “편한 모든 권한”을 주는 단계는 끝났다고 봐야 한다. 외부 도구 출력은 데이터로 고정하고, 실행은 샌드박스와 승인 게이트 뒤로 보내고, 시크릿은 기본적으로 숨기고, 작업 로그는 남겨야 한다.
앞으로 좋은 개발팀의 차이는 어떤 모델을 쓰느냐보다 어떤 작업장을 만들었느냐에서 갈릴 가능성이 크다. Agentjacking은 그 신호를 꽤 선명하게 보여준다. 에이전트가 똑똑해질수록 운영자는 더 단단한 경계와 증거를 설계해야 한다. 빠른 자동화는 여전히 좋다. 다만 이제는 빠르게 실행하는 능력보다, 실행하지 말아야 할 것을 멈추는 능력이 더 중요해졌다.