mimalloc 메모리 할당자가 다시 눈에 들어왔다. 처음엔 “malloc을 더 빠르게 바꾸는 라이브러리” 정도로 넘기기 쉬운데, 요즘 서버 워크로드를 생각하면 이야기가 꽤 현실적이다. CPU는 남아 있는데 지연 시간이 흔들리고, RSS는 천천히 올라가고, 긴 시간 돌린 서비스에서 메모리 조각화가 의심될 때가 있다. 그 순간부터 allocator는 갑자기 애플리케이션 코드만큼 중요해진다.
이번 주 GeekNews 상단에 microsoft/mimalloc이 올라왔고, 마침 Microsoft Research의 정리 글도 다시 돌았다. 글을 읽으면서 느낀 건 이거다. mimalloc은 신기술이라서 뜬 게 아니라, 우리가 돌리는 서비스의 메모리 패턴이 더 거칠어졌기 때문에 다시 보이는 쪽에 가깝다.
이전에 Docker 컨테이너 최적화를 다룰 때는 이미지 크기와 런타임 보안 쪽을 봤다. 이번엔 조금 더 아래 층이다. 컨테이너 안에서 프로세스가 메모리를 어떻게 잡고, 비우고, 다시 쓰는지의 문제다.
mimalloc이 다시 주목받는 이유
새롭다기보다, 워크로드가 변했다
mimalloc 자체는 갑자기 튀어나온 프로젝트가 아니다. Microsoft Research 쪽에서 Lean과 Koka 같은 언어 런타임을 위해 만들었고, 지금은 NoGIL CPython 3.13+, Unreal Engine, Microsoft 내부 서비스 같은 곳에서도 쓰인다. GitHub 저장소 기준으로도 이미 꽤 성숙한 오픈소스다.
그런데 2026년에 이 얘기가 다시 재밌어진 이유가 있다. 요즘 서비스는 대체로 더 많은 스레드, 더 큰 메모리 풋프린트, 더 긴 프로세스 수명을 가진다. 여기에 AI 쪽 워크로드가 붙으면서 수백 GB 단위의 메모리, 수백 개의 active thread, 짧고 많은 객체 할당이 같이 움직인다. 이런 환경에서는 “기본 malloc이면 충분하지 않나?”라는 말이 예전보다 덜 안전하다.
내가 특히 봤던 건 Microsoft Research 글의 서비스 워크로드 설명이다. 단순 벤치마크에서 빠른 allocator가 아니라, 오래 도는 대형 서비스에서 committed memory와 live data 사이의 간격을 줄이는 쪽에 힘을 주고 있다. 이건 실제 운영에서 중요하다. 메모리 사용량 그래프가 천천히 벌어지면 사람은 먼저 leak을 의심한다. 그런데 가끔은 leak이 아니라 allocator의 재사용 패턴, thread 간 반환, fragmentation이 문제다.
malloc 교체는 쉬워 보이지만, 영향 범위가 넓다
mimalloc이 매력적인 이유 중 하나는 drop-in replacement라는 점이다. Linux 계열에서는 LD_PRELOAD로 기존 프로그램의 malloc과 free를 가로채 볼 수 있다. 코드 수정 없이 실험할 수 있다는 말이다.
근데 이게 함정이기도 하다. 바꾸기는 쉬운데, 바뀌는 범위가 넓다. 애플리케이션 코드, 서드파티 라이브러리, C extension, native module, 런타임 내부 할당까지 한꺼번에 영향을 받는다. 특히 Python, Node.js native addon, C++ 서비스처럼 여러 계층이 섞인 프로그램에서는 “성능이 좋아졌다”와 “어디선가 subtle bug가 드러났다”가 같이 올 수 있다.
그래서 나는 mimalloc을 보고 바로 production에 넣자는 쪽은 아니다. 대신 의심할 만한 증상이 있는 서비스에서 아주 좋은 실험 도구라고 본다. RSS가 계속 출렁인다. thread 수가 많다. allocation churn이 크다. latency tail이 GC나 I/O만으로 설명되지 않는다. 이런 상황이면 한 번쯤 allocator를 바꿔 계측해볼 가치가 있다.
서버 메모리 병목은 어디서 생기나
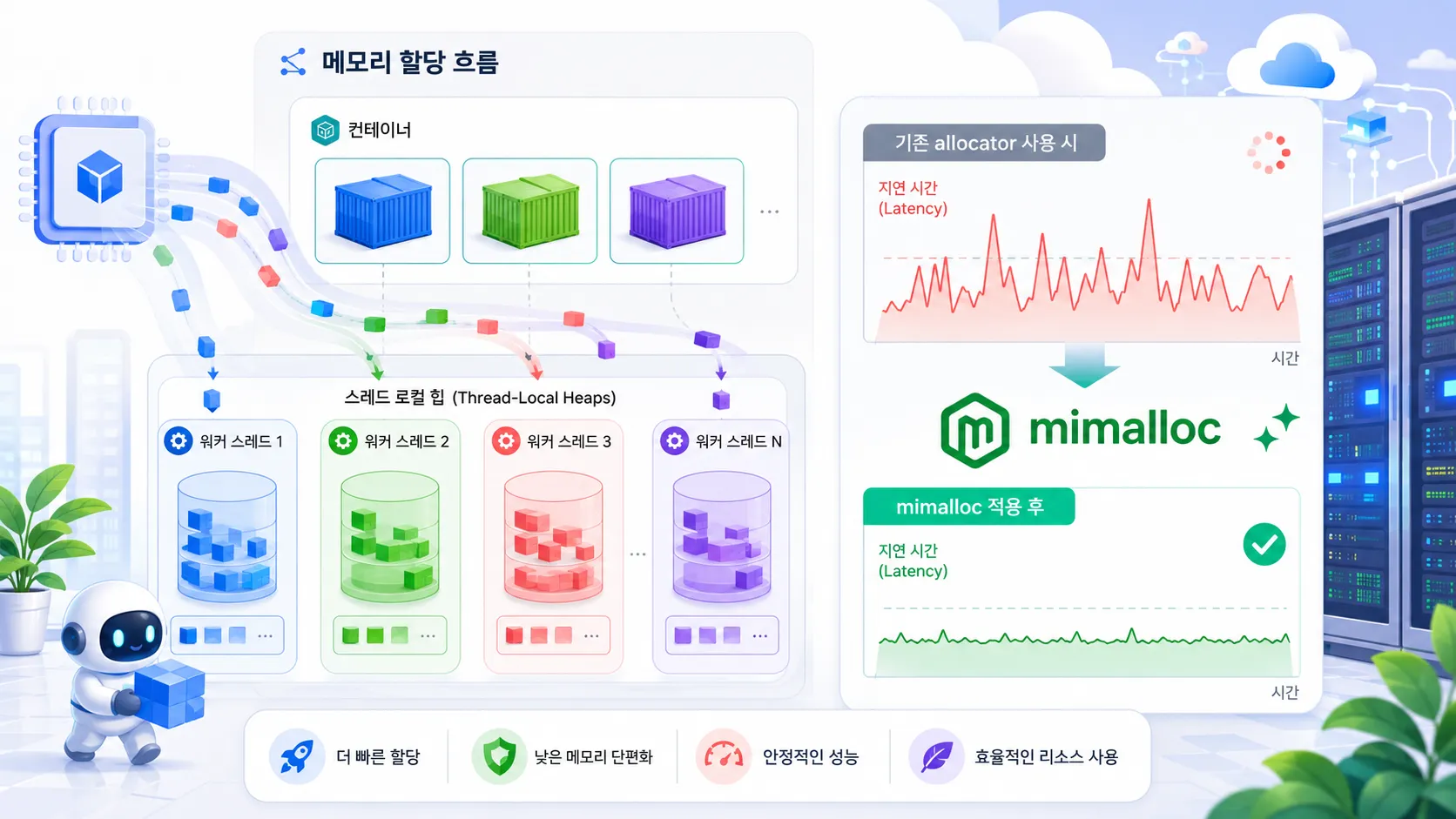
thread-local heap은 빠르지만, 공유가 어렵다
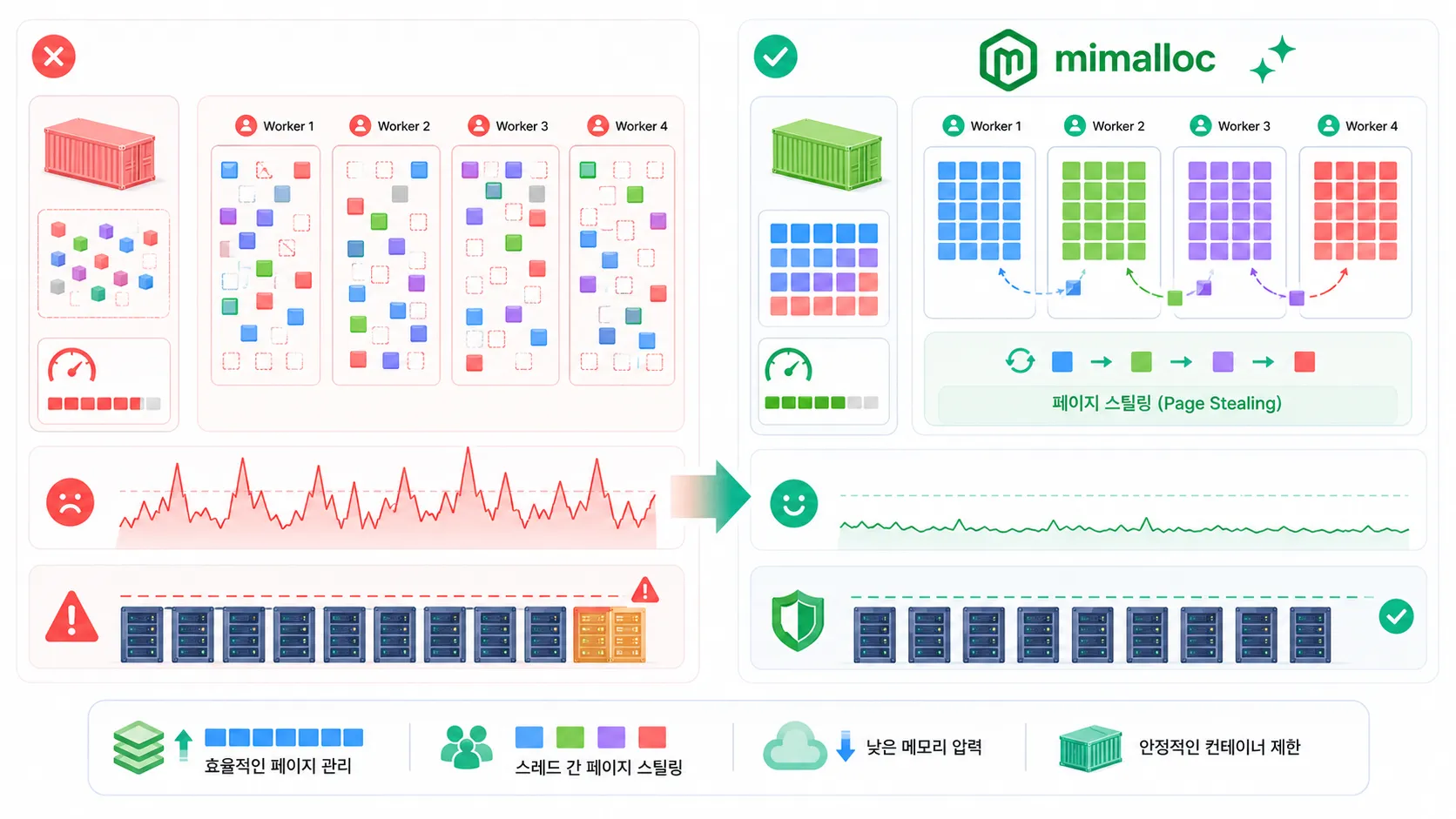
대부분의 고성능 allocator가 비슷한 고민을 한다. 각 thread가 자기 heap을 갖고 있으면 빠르다. lock을 덜 잡고, cache locality도 좋아진다. 같은 thread에서 할당하고 해제하는 객체가 많다면 성능이 잘 나온다.
문제는 현실의 서비스가 그렇게 얌전하지 않다는 점이다. 한 thread에서 만든 객체를 다른 thread가 해제한다. 작업 큐를 타고 넘어가고, async runtime을 거치고, worker pool에서 처리된다. 이때 thread-local 구조가 너무 강하면 메모리를 잘 공유하지 못해서 남는 블록이 한쪽에 쌓이고, 다른 쪽은 새 메모리를 요청한다.
mimalloc은 이 균형을 꽤 진지하게 다룬다. page 단위 free list를 잘게 나누고, cross-thread free 경로를 atomic operation으로 처리하고, 필요하면 page ownership을 넘기는 식으로 성능과 메모리 재사용 사이의 간격을 줄인다. 여기서 중요한 건 “무조건 빠른 allocator”가 아니라는 점이다. 빠른 경로를 유지하면서도 오래 도는 서비스에서 메모리가 한쪽에 갇히지 않게 하는 쪽이 핵심이다.
committed memory와 live data를 같이 봐야 한다
운영에서 흔히 놓치는 지표가 있다. live data는 실제로 살아 있는 데이터에 가깝고, committed memory는 allocator와 OS 사이에서 확보된 메모리다. 둘이 어느 정도 차이 나는 건 자연스럽다. 문제는 그 차이가 계속 벌어지거나, 트래픽이 내려간 뒤에도 줄지 않는 경우다.
Microsoft Research 글에서 흥미로웠던 부분도 이 지점이다. 어떤 allocator는 처리량은 잘 나오지만 live data보다 훨씬 많은 메모리를 붙잡을 수 있고, 기본 allocator는 메모리 공유는 괜찮지만 대량 concurrent allocation에서는 처리량이 낮을 수 있다. mimalloc 최신 흐름은 이 둘 사이에서 더 나은 타협점을 찾는 쪽이다.
이건 클라우드 비용과도 바로 연결된다. 애플리케이션은 같은 일을 하는데 컨테이너 memory limit을 더 높여야 한다면, 그건 곧 비용이다. Kubernetes에서 OOMKilled가 가끔 터지고, 원인을 못 찾고, 결국 request/limit을 올리는 식으로 해결했다면 allocator 계층도 한 번 의심해볼 만하다.
도입 전에 먼저 해볼 실험
LD_PRELOAD로 짧게 붙여본다
가장 편한 실험은 별도 코드 변경 없이 실행해보는 것이다. 패키지 배포 방식은 환경마다 다르지만, 핵심은 기존 바이너리에 mimalloc shared library를 먼저 물리는 것이다.
LD_PRELOAD=/usr/lib/libmimalloc.so MIMALLOC_SHOW_STATS=1 ./your-service
컨테이너라면 entrypoint에서만 바꿔도 된다. 다만 이 실험은 staging이나 shadow traffic에서 먼저 해야 한다. allocator 교체는 작게 보여도 runtime 전체에 걸리는 변경이다. 특히 이미 다른 allocator를 정적으로 링크한 라이브러리가 있거나, sanitizer, profiler, APM agent가 메모리 할당을 추적하고 있다면 충돌 가능성을 봐야 한다.
나는 이 실험을 할 때 평균 응답 시간보다 tail latency를 먼저 본다. p95, p99, p999가 어떻게 움직이는지 봐야 한다. allocator 교체가 평균을 조금 좋게 만들고 tail을 망가뜨리면 운영에서는 별로다. 반대로 평균은 비슷한데 p99가 안정되면 꽤 의미가 있다.
비교 지표를 미리 정해둬야 한다
allocator 실험에서 제일 싫은 결과는 “느낌상 빨라진 것 같다”다. 이건 거의 쓸모가 없다. 최소한 비교 지표를 미리 정해야 한다.
| 지표 | 봐야 하는 이유 |
|---|---|
| RSS와 virtual memory | 실제 프로세스 메모리 압박과 주소 공간 사용을 분리해서 보기 |
| p95/p99 latency | 평균이 숨기는 tail 흔들림 확인 |
| allocation/free rate | 할당 churn이 큰 구간과 트래픽 패턴 연결 |
| page fault와 CPU 사용률 | allocator 교체가 OS 메모리 동작에 주는 영향 확인 |
| OOMKilled/재시작 횟수 | Kubernetes 환경에서 체감 안정성 확인 |
이 표를 너무 거창하게 만들 필요는 없다. 중요한 건 같은 트래픽, 같은 배포, 같은 warm-up 조건에서 비교하는 것이다. allocator는 초기 구동 직후와 몇 시간 지난 뒤의 모습이 다를 수 있다. 짧은 벤치마크만 보고 결론을 내리면 장기 서비스에서 틀릴 때가 많다.
보안 모드는 보너스지만 만능은 아니다
secure mode가 잡아주는 것들
mimalloc 저장소를 보면 secure mode가 꽤 눈에 띈다. guard page, randomized allocation, encoded free list, double free detection 같은 완화책을 제공한다. heap metadata가 overflow로 바로 망가지지 않게 하고, free list overwrite 같은 공격을 어렵게 만드는 방향이다.
이건 좋은 기능이다. 특히 C/C++ 서비스나 native extension이 많은 시스템에서는 allocator 계층의 방어가 의미 있다. 다만 secure mode를 켰다고 memory safety 문제가 사라지는 건 아니다. 성능 비용도 있고, 모든 취약점을 막는 것도 아니다. allocator 보안 기능은 방탄복에 가깝지, 버그 없는 코드를 대신 만들어주는 마법은 아니다.
그래서 보안 목적으로 mimalloc을 볼 때도 순서는 분명해야 한다. ASAN, Valgrind, fuzzing, 코드 리뷰, 의존성 업데이트가 먼저다. secure mode는 그 위에 얹는 추가 방어선이다. 이 순서가 바뀌면 도구가 주는 안정감 때문에 더 위험한 결정을 할 수 있다.
전역 override는 디버깅을 더 어렵게 만들 수도 있다
LD_PRELOAD로 전역 override를 걸면 편하다. 하지만 디버깅할 때는 복잡성이 늘어난다. crash dump를 볼 때 allocator 내부 프레임이 섞이고, 기존 memory profiler와 결과가 달라지고, 특정 라이브러리가 기대하던 할당/해제 경계가 달라질 수 있다.
특히 여러 언어가 섞인 서비스에서 조심해야 한다. 예를 들어 Python 프로세스에 C extension이 붙고, 그 안에서 별도 native library가 또 메모리를 관리하는 구조라면 단순하지 않다. 어느 계층이 할당하고 어느 계층이 해제하는지 경계가 애매하면 allocator 교체가 숨어 있던 문제를 드러낼 수 있다. 좋은 일이기도 하지만, 배포 전에는 귀찮은 일이 된다.
팀에서 적용 여부를 판단하는 기준
성능 문제가 allocator 문제인지 먼저 좁힌다
mimalloc을 쓰기 전에 해야 할 일은 “우리가 allocator 문제를 겪고 있는가”를 좁히는 것이다. 성능이 느리다고 무조건 allocator를 바꾸면 안 된다. DB query, cache miss, lock contention, GC pause, network retry가 원인인데 allocator만 바꾸면 문제를 흐릴 수 있다.
내 기준은 이렇다. 메모리 사용량이 트래픽과 다르게 움직인다. 같은 live workload인데 committed memory가 과하게 벌어진다. 스레드가 많고 객체 생명주기가 짧다. 장시간 실행 후 latency tail이 나빠진다. 이런 신호가 두세 개 겹치면 allocator 실험을 할 만하다.
반대로 단순 CRUD API, 메모리 footprint가 작고, 대부분의 병목이 DB나 외부 API에 있는 서비스라면 우선순위가 낮다. 이런 경우에는 allocator보다 query plan, connection pool, cache key, 배포 이미지 크기 같은 쪽이 더 빨리 먹힌다.
성공 기준은 “빠름”보다 “안정됨”이다
allocator 교체의 성공 기준을 throughput 하나로 잡으면 위험하다. 운영에서는 안정성이 더 중요할 때가 많다. p99가 줄었는가. memory limit을 낮출 수 있는가. OOMKilled가 줄었는가. 재시작 후 warm-up이 예측 가능한가. profiler와 crash dump가 계속 읽을 만한가.
나는 특히 “limit을 낮출 수 있는가”를 좋아한다. 클라우드에서는 이게 바로 돈이기 때문이다. 같은 부하에서 컨테이너 memory request를 20% 낮출 수 있고, tail latency가 흔들리지 않는다면 그건 꽤 직접적인 성과다. 반대로 벤치마크 숫자는 예쁜데 운영 limit을 그대로 둬야 한다면 팀 입장에서는 별로 체감이 없다.
마치며
메모리 할당자는 지루하지만, 지루해서 중요하다
mimalloc이 다시 주목받는 걸 보면서 제일 먼저 든 생각은 “인프라는 결국 지루한 층으로 돌아오는구나”였다. 요즘은 AI 에이전트, 새 프레임워크, 멋진 개발 도구 이야기가 많다. 그런데 실제 서비스를 오래 돌리다 보면 결국 malloc, page, thread, RSS, cache locality 같은 단어로 내려온다.
이건 화려하지 않지만 중요하다. 좋은 allocator 하나가 잘못된 아키텍처를 구해주지는 못한다. 하지만 이미 잘 만든 서비스에서 남아 있는 지연 시간과 메모리 비용을 줄이는 데는 꽤 날카로운 도구가 될 수 있다.
지금 해볼 일은 교체가 아니라 계측이다
내 결론은 단순하다. mimalloc을 바로 넣자는 게 아니다. allocator 계층을 성능 점검 목록에 올려두자는 것이다. 특히 장시간 실행되는 서버, worker pool이 큰 서비스, native dependency가 많은 런타임, 메모리 limit 때문에 자주 싸우는 컨테이너에서는 실험 가치가 있다.
다만 성공하려면 순서가 필요하다. 먼저 현재 allocator에서 RSS, p99, page fault, restart를 재고, 그다음 mimalloc을 같은 조건에서 붙여본다. 개선이 보이면 더 긴 soak test로 간다. 문제가 없고 운영 지표가 좋아지면 그때 배포를 고민한다.
mimalloc의 장점은 “무조건 빠르다”보다 “생각보다 낮은 비용으로 깊은 층을 실험할 수 있다”에 가깝다. 이 정도면 이번 주에 다시 볼 이유는 충분하다.