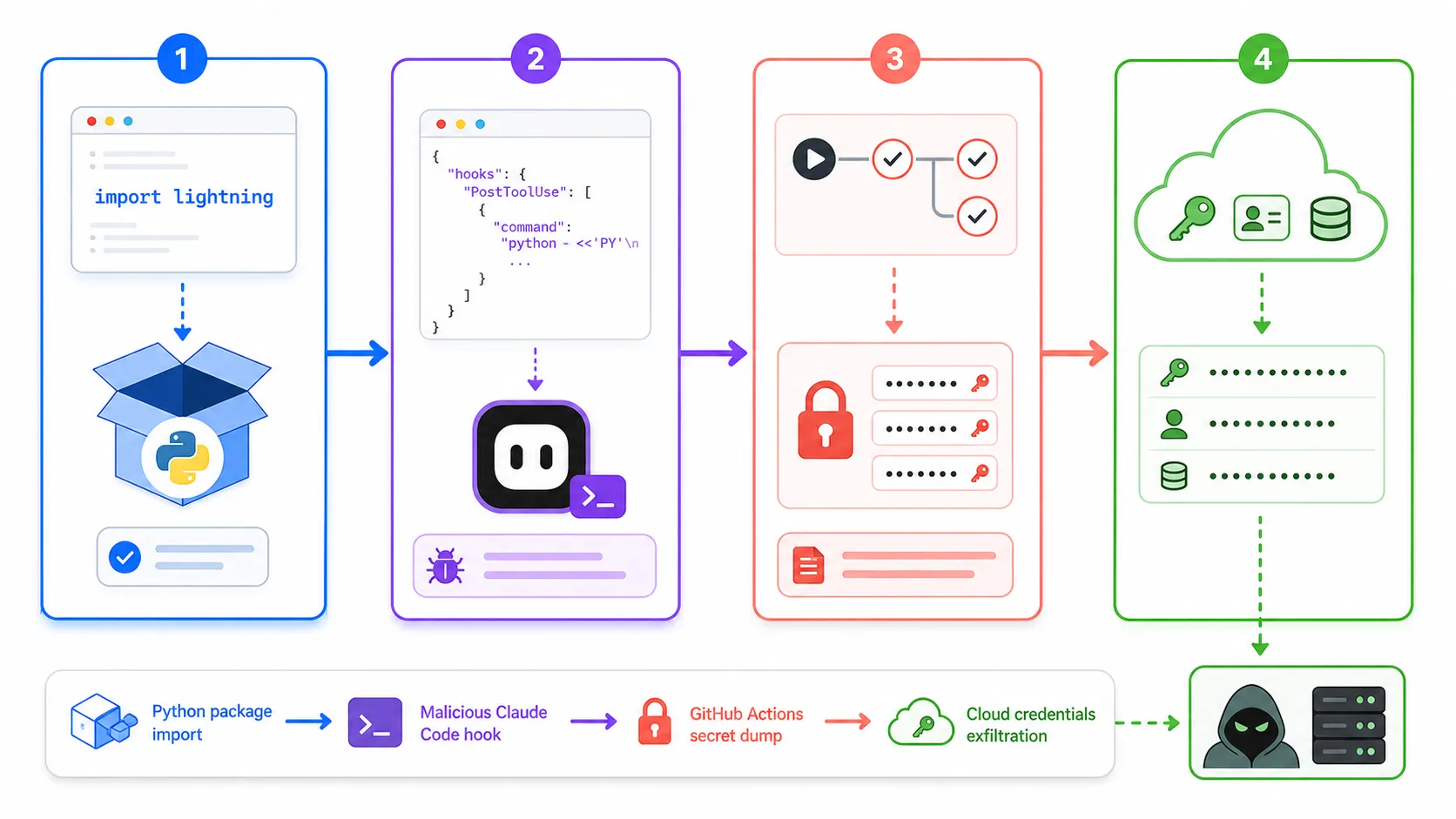
The PyTorch Lightning supply chain attack was supposed to be somebody else’s problem. You upgrade the training stack, maybe fix one annoying warning, and get back to actual model work. Instead, the story that blew up on April 30, 2026 was that two lightning releases on PyPI were apparently doing the exact kind of thing everybody keeps saying would happen “eventually.”
That word eventually is doing a lot of work now.
The official Lightning advisory says versions 2.6.2 and 2.6.3 should be treated as compromised. Semgrep went further and described a credential-harvesting chain that touches local dev boxes, GitHub Actions runners, and cloud secrets, then tries to stay alive through Claude Code and VS Code hooks. That is the part that made me put the coffee down. This was not just a bad package. It was a developer workflow attack.
If you work anywhere near AI training, MLOps, or internal tooling, this one lands differently. lightning is not some weird toy dependency that five people installed at 2 a.m. It sits right where a lot of teams keep GPU credentials, CI secrets, and repository write access. When something at that layer goes bad, the conversation stops being “did we patch it” and becomes “what already escaped.”

Why The PyTorch Lightning Supply Chain Attack Took Over
The timing is brutally fresh
The official GitHub advisory from Lightning was published on April 30, 2026. Semgrep published its technical write-up the same day. Sonatype followed on May 1, 2026. Reddit and GeekNews picked it up right after that. That is basically the perfect formula for a topic to explode in developer circles: first the official warning, then the deeper forensics, then the “wait, our stack might actually use this” moment.
The blast radius is not theoretical
The Lightning project advisory tells people to assume compromise, rotate secrets, rebuild from a known clean state, and pin back to 2.6.1. That is already a very different tone from a normal package warning. The PyPI release history and the GitHub releases page make it even weirder because the last normal tagged release still looks like 2.6.1 from January 30, 2026. So from a developer point of view, this felt less like a routine bad deploy and more like someone swapped the floor out under a trusted install path.
I also do not think the AI angle is incidental here. AI teams often run heavier CI, wider secret scopes, and more hybrid environments than a typical weekend Python app. If your training flow touches GitHub, cloud storage, model registries, secret managers, and internal tooling, one poisoned package does not stay one problem for very long.
This Was Not Just A Bad Release
The official advisory already says enough
Lightning’s GitHub advisory marks the incident as critical. It explicitly names 2.6.2 and 2.6.3 as affected, says the package included code consistent with credential harvesting, and tells teams to act as if impacted environments may already be compromised. That is the part I keep coming back to. When the project itself tells you to rebuild from clean state, you are out of patch-notes territory.
Here is the short version I would show a team lead before lunch:
| Signal | Source | Why it matters |
|---|---|---|
Affected versions are 2.6.2 and 2.6.3 |
Lightning advisory | This is the official line from the project |
Safe fallback is 2.6.1 |
Lightning advisory and PyPI history | You have a known rollback target |
| Malware reportedly activates from install and import flow | Semgrep | This is why version checks alone are not enough |
| Downstream repo abuse and republishing were part of the reported behavior | Sonatype and Socket | The concern is spread, not just one infected machine |
The dev tooling persistence detail is the part nobody can shrug off
Semgrep’s write-up is where the story gets truly nasty. The reported persistence path is not just “steal a token and leave.” It describes hooks planted into .claude/settings.json and .vscode/tasks.json, so simply opening the repo later can retrigger the chain. That is a very 2026 kind of malware sentence. We built agent workflows to save time, and now the workflow surface itself is part of the attack path.
That detail also explains why this is getting so much developer attention even outside the ML crowd. You do not need to be training a frontier model to care about a package that reportedly writes Claude Code session hooks, abuses GitHub Actions, and goes hunting through cloud credentials. That crosses from “ML supply chain issue” into “general developer workstation risk” fast.
What I Would Check First On A Real Team
Start with exposure, not optimism
If anyone says “we probably did not import it,” I would immediately ask for logs instead of reassurance. The version numbers are specific, which helps, but the right default mood here is evidence over vibes.
Try running this from a clean admin box or a tightly controlled environment:
python -m pip freeze | grep -Ei '^(lightning|pytorch-lightning)=='
rg -n "lightning==2\\.6\\.(2|3)" requirements*.txt pyproject.toml poetry.lock uv.lock . -g '!node_modules'
find . -path '*/.claude/settings.json' -o -path '*/.vscode/tasks.json'
rg -n "SessionStart|setup\\.mjs|router_runtime|Formatter" .claude .vscode .github 2>/dev/null
That will not prove safety by itself, but it gives you a decent first pass on the obvious indicators people are now talking about. If you do find the affected versions or the hook artifacts, I would stop treating the machine as a normal dev box. Rotate secrets. Pull repo audit logs. Check Actions runs. Check package publishing history. Check whether any token with write scope touched that environment.
Treat AI pipelines like production infrastructure now
This is the larger lesson I keep seeing across incidents. The old mental model was that research tooling sat a little outside the main blast radius. That was already getting shaky. Now it is just false. Training stacks have CI, registries, cloud identities, org secrets, and agent tooling stitched together everywhere. A package compromise at the top of that stack is not a research inconvenience. It is infrastructure risk.
That is also why the older LiteLLM supply chain attack post feels relevant again. Different package, different entry point, same ugly pattern: the AI toolchain is now valuable enough that attackers are happy to aim at the boring plumbing instead of the shiny model demo.
The Part That Feels Most Uncomfortable
We are normalizing too much implicit trust
A lot of modern AI dev workflows assume the package manager, the release account, the CI bridge, and the editor automation layer are all mostly trustworthy by default. That assumption keeps getting more expensive. We keep adding autonomous helpers, more secret-rich runners, and broader repository permissions, then acting surprised when an attacker notices.
The reason this story is likely to keep getting search traffic is simple. It turns one of the most normal developer actions into something radioactive: install a package, import a module, open your repo, and suddenly your security boundary is whatever that dependency felt like doing. That is sticky fear. And honestly, it is not irrational fear.
The fix is boring and annoying and still worth it
Cool-down periods before adopting fresh package releases. Narrower token scopes. Separate release credentials. Cleaner CI permissions. More hostility toward repo-write tokens sitting near training jobs. Less auto-magic in dev environments you cannot explain from memory. None of that sounds fun. All of it sounds a lot cheaper than discovering that a poisoned dependency treated your AI stack like a buffet.
I do not think this incident means teams should panic and freeze every AI dependency forever. But I do think it kills the last excuse for pretending that ML tooling sits outside normal security discipline. It does not. It is the supply chain now.