“GPT? 그거 수십억 파라미터에 수만 줄 코드 아니야?”
나도 그렇게 생각했다. 그런데 2월 12일, AI계의 전설 Andrej Karpathy가 트위터에 올린 한 줄이 개발자 커뮤니티를 뒤집어 놓았다.
“Train and inference GPT in 243 lines of pure, dependency-free Python. This is the full algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.”
PyTorch 없다. TensorFlow 없다. NumPy조차 없다. 순수 파이썬 243줄로 GPT를 학습시키고 텍스트를 생성한다. 이 말을 처음 들었을 때 솔직히 “장난하나?” 싶었다. 근데 진짜였다.

Karpathy는 왜 이걸 만들었나
Andrej Karpathy. 전 Tesla AI 디렉터, 전 OpenAI 연구원, 스탠포드 CS231n의 전설적 강의자. 이 사람이 10년간 만들어온 프로젝트들의 계보를 보면 microgpt가 왜 나왔는지 이해된다.
- micrograd — 자동 미분 엔진을 밑바닥부터 구현
- makemore — 문자 수준 언어 모델 처음부터 만들기
- nanoGPT — 최소한의 GPT 학습 코드 (하지만 PyTorch 필요)
그가 10년간 파고든 핵심 질문은 하나였다: “GPT의 알고리즘적 본질은 대체 뭐냐?”
microgpt는 그 답이다. “이 이상 단순하게 만들 수 없다”는 그의 선언은 허세가 아니었다. 외부 라이브러리를 전부 걷어내고 나니, GPT의 핵심 알고리즘이 243줄 안에 전부 들어갔다.
243줄 안에 뭐가 들어있나
microgpt.py 하나에 GPT를 구성하는 모든 것이 압축되어 있다. 하나씩 뜯어보자.
1. Autograd (자동 미분 엔진)
딥러닝의 심장은 역전파(Backpropagation)다. PyTorch가 해주던 그 일을 Karpathy는 Value 클래스 하나로 해결했다.
class Value:
def __init__(self, data, children=(), local_grads=()):
self.data = data
self.grad = 0
self._children = children
self._local_grads = local_grads
모든 산술 연산(덧셈, 곱셈, 거듭제곱, 로그, 지수, ReLU)이 계산 그래프에 기록된다. backward()를 호출하면 위상 정렬로 그래프를 역순 탐색하면서 연쇄 법칙(Chain Rule)을 적용한다. PyTorch의 torch.autograd가 하는 일의 본질이 바로 이거다.
2. 토크나이저
uchars = sorted(set(''.join(docs)))
BOS = len(uchars)
vocab_size = len(uchars) + 1
BPE? SentencePiece? 전부 효율성을 위한 것이다. 알고리즘의 본질만 놓고 보면 문자 하나를 정수 하나에 매핑하는 것으로 충분하다. 32,000개의 인간 이름 데이터셋을 사용해서 한 글자씩 토큰화한다.
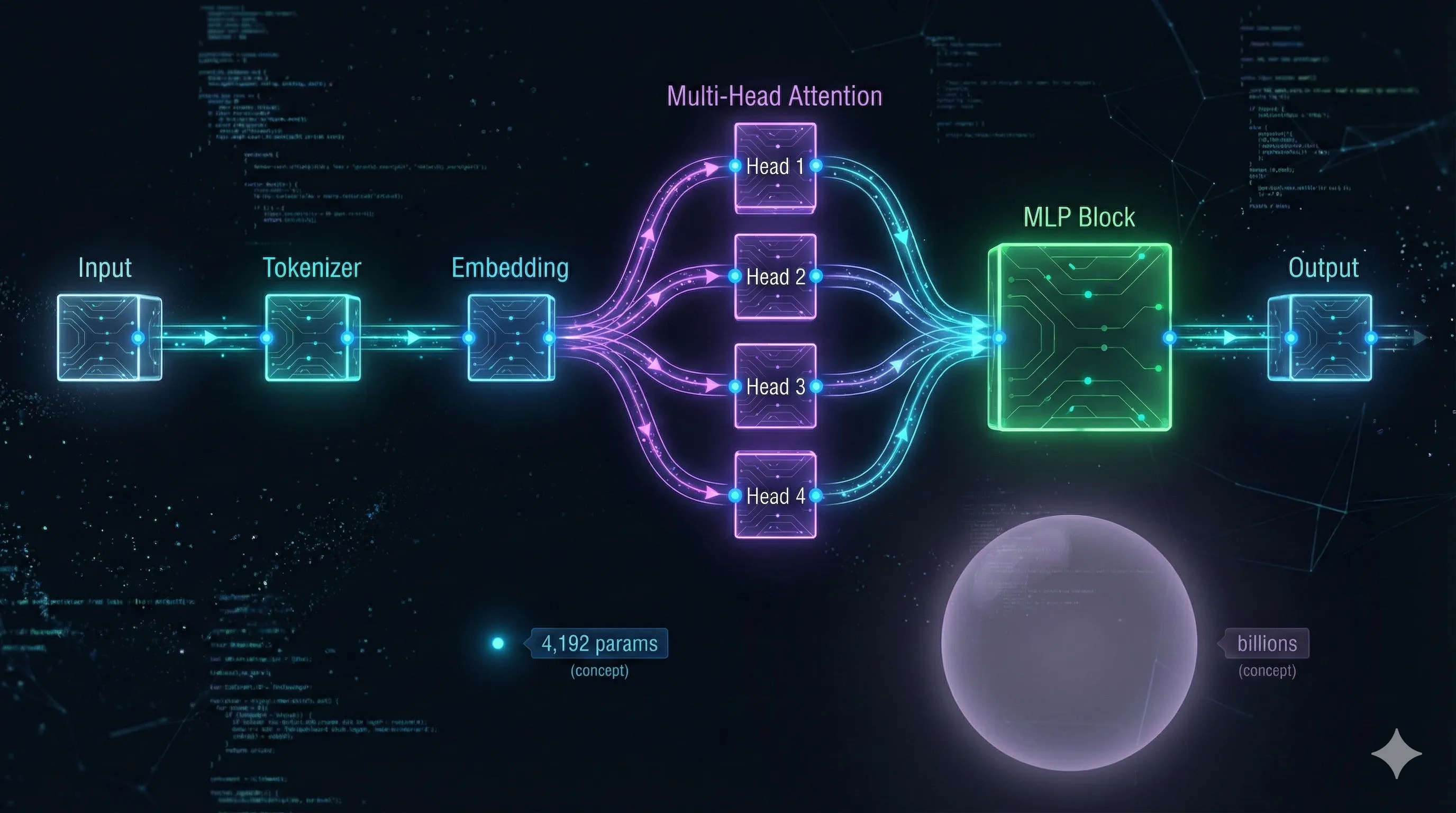
3. GPT 아키텍처
토큰 임베딩, 위치 임베딩, 멀티헤드 어텐션, MLP 블록, 출력층. 이 전부가 순수 파이썬 함수로 구현되어 있다.
def gpt(token_id, pos_id, keys, values):
# 토큰 임베딩 + 위치 임베딩
x = [t + p for t, p in zip(tok_emb, pos_emb)]
for li in range(n_layer):
# Multi-Head Attention
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
# Softmax → 가중합 → 잔차 연결
# MLP 블록 (Linear → ReLU → Linear)
# 잔차 연결
return linear(x, state_dict['lm_head'])
4,192개 파라미터. 1개 레이어, 16차원 임베딩, 4개 어텐션 헤드. ChatGPT의 1,750억 파라미터와 비교하면 미세먼지 같은 크기지만, 알고리즘은 완전히 동일하다.
직접 돌려보면 벌어지는 일
microgpt를 실행하면 32,000개의 이름 데이터를 학습한 후, 새로운 이름을 생성한다. 학습 과정은 이렇다.
for step in range(num_steps):
# 문서 하나를 골라서 토큰화
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
# 각 토큰을 순차적으로 모델에 입력
for pos_id in range(n):
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
# 역전파로 기울기 계산
loss.backward()
# Adam 옵티마이저로 파라미터 업데이트
for i, p in enumerate(params):
m[i] = beta1 * m[i] + (1 - beta1) * p.grad
v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2
p.data -= lr_t * m[i] / (v[i] ** 0.5 + eps)
학습이 끝나면 BOS 토큰에서 시작해 한 글자씩 샘플링하며 새 이름을 생성한다. 온도(temperature) 파라미터로 창의성을 조절한다. 0.5면 보수적, 1.0이면 자유분방하게 생성한다.
놀라운 건 이 미니어처 모델이 실제로 그럴듯한 이름을 만들어낸다는 것이다. “Sarah”나 “Michael”을 외운 게 아니라, 영어 이름의 패턴(자음-모음 조합, 일반적 접두사/접미사)을 통계적으로 학습한 거다.
이게 왜 충격적이냐면
Karpathy가 microgpt 블로그에서 던진 핵심 통찰이 있다.
“ChatGPT와 microgpt의 차이는 규모의 문제이지, 알고리즘의 문제가 아니다.”
이 한 줄이 머리를 때렸다. 우리가 매일 쓰는 GPT-4, Claude, Gemini — 이것들의 핵심 알고리즘이 243줄짜리 파이썬 파일 하나에 전부 담겨 있다는 뜻이다. 수만 줄의 CUDA 커널, 분산 학습 코드, 메모리 최적화 — 이것들은 전부 “효율성”을 위한 엔지니어링이지, 알고리즘 자체는 아니다.
또 하나 소름끼치는 포인트가 있다. AI의 환각(hallucination) 문제. Karpathy는 이렇게 설명한다.
“환각은 버그가 아니다. 훈련 데이터에서 통계적으로 그럴듯한 완성을 만들어내는 것이 모델이 하는 일의 전부다.”
microgpt가 “Zariah”라는 존재하지 않는 이름을 생성할 때, 그건 모델이 망가진 게 아니다. 영어 이름의 통계적 패턴을 따라 “그럴듯한 새 이름”을 만든 것이다. GPT-4가 존재하지 않는 논문을 인용하는 것도 본질적으로 같은 메커니즘이다. 규모만 다를 뿐.
개발자에게 던지는 메시지
microgpt를 보고 나면 딥러닝이 다르게 보인다.
첫째, 프레임워크는 도구일 뿐이다. PyTorch, TensorFlow, JAX — 이것들은 GPU 위에서 행렬 연산을 빠르게 하기 위한 도구다. 알고리즘을 이해하는 데 필수가 아니다. microgpt는 순수 파이썬 for문으로 행렬 곱을 하면서도 올바르게 동작한다. 느릴 뿐이다.
둘째, GPT를 이해하고 싶다면 microgpt부터 읽어라. Attention is All You Need 논문 100번 읽는 것보다 이 243줄 코드를 한 번 돌려보는 게 이해에 더 도움된다. 토큰이 어텐션을 거치면서 어떻게 변환되는지, 역전파가 어떻게 기울기를 계산하는지, Adam이 왜 SGD보다 나은지 — 전부 코드 한 줄 한 줄에 녹아있다.
셋째, AI 시대에 진짜 경쟁력은 본질을 꿰뚫는 능력이다. model.fit() 한 줄로 학습시키는 건 누구나 한다. 그 안에서 무슨 일이 벌어지는지 아는 사람은 드물다. Karpathy가 10년간 보여준 건 바로 이거다 — 겉핥기가 아닌 본질 이해.
마치며
243줄. 외부 의존성 제로. 순수 파이썬.
Karpathy의 microgpt는 단순한 토이 프로젝트가 아니다. 이건 “GPT의 본질은 이거다”라는 10년짜리 연구의 최종 답안이다. 수천억 파라미터, 수만 GPU 클러스터, 수백억 달러 투자 — 이 모든 화려함 뒤에 있는 알고리즘의 핵심이 243줄에 담겨있다는 사실이 경외감과 동시에 허탈함을 준다.
microgpt.py를 GitHub Gist에서 직접 받아서 돌려보길 강력히 권한다. 파이썬만 설치되어 있으면 된다. pip install 아무것도 필요 없다. 코드를 한 줄씩 따라가다 보면, “아 GPT가 이런 거였구나” 하는 순간이 반드시 온다.
그 순간, 당신의 AI에 대한 시야가 완전히 달라질 것이다.