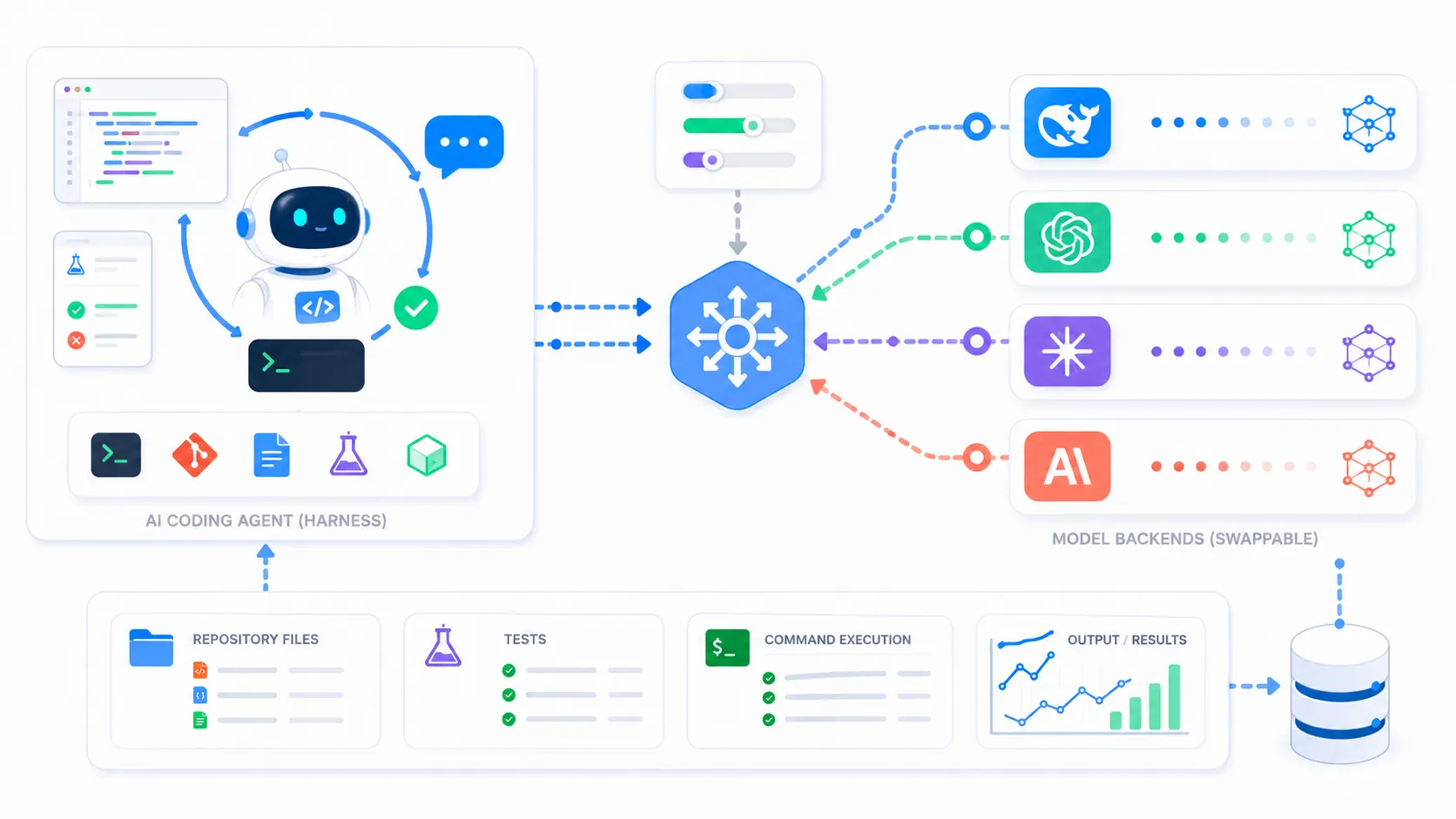
DeepClaude hit the developer internet this week because it says the quiet part out loud: a coding agent is not just a model. It is a harness, a tool loop, a pile of environment variables, a terminal session, and a billing event that keeps happening while you are trying to fix one stupid test.
The spicy version is easy to share. DeepClaude points Claude Code at DeepSeek V4 Pro and claims roughly 17x lower cost while keeping the same Claude Code workflow. Same shell. Same file edits. Same bash calls. Same multi-step agent loop. Different model bill.
That is catnip for developers right now. Not because everyone has suddenly become a procurement expert. Because a lot of us have spent the last three months discovering that agentic coding cost is not a theory problem. It is a daily engineering constraint. I wrote about the same pressure in the Uber AI coding cost reset, and DeepClaude feels like the open-source answer people were already reaching for.

The repo is small enough to make the whole thing feel a little illegal, even though the trick is mostly boring. Claude Code reads backend configuration from environment variables. DeepClaude rewrites those variables for the session, launches Claude Code, and restores things when you exit. The useful weirdness is not the script. The useful weirdness is that the most valuable part of the product may be separable from the model vendor.
Why DeepClaude Blew Up This Week
The cost claim is simple enough to remember
The headline number landed because it is legible: DeepSeek V4 Pro is dramatically cheaper than Anthropic API pricing for comparable agent-loop workloads. DeepSeek’s own API pricing page lists V4 Pro at discounted May pricing of $0.435 per million input tokens and $0.87 per million output tokens, with the 75 percent discount extended until May 31, 2026. That is temporary, but even the crossed-out full price is still far below premium frontier-model API prices.
And with agents, output price is only half the story. The expensive part is the loop. Every tool call adds context. Every test result becomes more input. Every failed attempt becomes another turn. If the model keeps a large repo map, tool schema, instructions, and logs in context, a “small bug fix” can become a surprisingly chunky token trace.
So when a wrapper says, “keep Claude Code’s body, swap the brain,” people listen.
The timing was perfect
DeepSeek V4 Pro shipped in late April with a one-million-token context window and agent-friendly pricing. Hugging Face’s DeepSeek V4 writeup framed the release around long-running agentic workloads, not just chat benchmarks. That matters. A model can be smart in a leaderboard and still painful as an agent if long contexts get expensive or brittle.
DeepClaude showed up right when developers were already arguing about Claude Code limits, Codex subscriptions, Cursor costs, and whether open models are finally good enough for ordinary repo work. Hacker News and Reddit did the predictable thing: half the comments treated it as liberation, half treated it as a quality trap, and a smaller useful slice asked what the boundary should be between harness and model.
That last question is the one I care about.
The Harness Is Becoming The Product
Claude Code is more than model access
The common lazy take is that DeepClaude proves models are commodities. I do not buy that. At least not yet.
What it actually proves is more specific: developers value the agent loop enough that they want to bring their own model behind it. Claude Code is useful because it can read files, edit files, run commands, inspect failures, call subagents, resume sessions, and keep a task moving through the repo. The model matters, obviously. But the workflow around the model matters more than people admitted a year ago.
That is why this little wrapper is interesting. It does not rebuild Claude Code. It does not offer a new IDE. It does not ask you to migrate your workflow. It just tries to decouple the expensive reasoning layer from the familiar execution layer.
Try looking at it like this:
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_AUTH_TOKEN="$DEEPSEEK_API_KEY"
export ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-v4-pro"
claude
That is not a product strategy by itself. It is a pressure test. If three environment variables can change the economics of an agent loop, then agent vendors have to explain what their lock-in is actually buying.
The tradeoff is not fake
There are real limitations. The DeepClaude README calls out degraded or missing behavior around image input, MCP server tools through the compatibility layer, and some parallel-tool behavior. It also says Claude Opus is still better for complex reasoning. That matches my instinct. I would not hand a gnarly architecture migration to the cheapest backend and call it a day.
But for routine work? Renames, tests, small refactors, log cleanup, docs, dependency bumps, single-feature slices? I can see why developers are tempted. Those tasks burn enough tokens to hurt, but they do not always need the best model on the planet.
That is the uncomfortable part for vendors. The market may not split into “best model wins” and “cheap model loses.” It may split by task class.
Where This Gets Messy Fast
Compatibility layers always have edges
Anthropic-compatible does not mean Anthropic-identical. Anyone who has dealt with OpenAI-compatible endpoints already knows the feeling. The request shape works, until it does not. Tool schemas work, until a model interprets one argument weirdly. Context caching exists, but the semantics are different. Streaming errors look similar, except when your client code expects one exact event.
That is fine for experiments. It is less fine when the agent is editing production code and the failure mode is “silently worse planning.”
The right way to use something like DeepClaude is not blind replacement. It is routing. Cheap backend for cheap tasks. Native backend for hard reasoning. Strong verification around both. If the harness can switch models by task type, then cost savings become a workflow feature instead of a stunt.
The subscription comparison is slippery
The 17x number is memorable, but I would not build a budget model from it without measuring my own traces. Subscription plans, API rates, cache hit rates, output-heavy tasks, long-running sessions, and promotional discounts all distort the math.
DeepSeek’s discount currently runs through May 31, 2026. OpenRouter and provider pricing can move. Claude Code subscription limits and Codex-style plans can change. A team doing twenty short tasks a day has a different cost curve than one running four eight-hour agents in parallel.
So yeah, the headline is clickable. The serious takeaway is more boring: agent teams need token observability. Not vibes. Actual per-task cost reports, model routing logs, cache-hit rates, retry counts, and review outcomes.
What I Would Actually Do With It
Start with boring tasks
If I were evaluating DeepClaude for a team, I would not begin with a large refactor. I would start with the work nobody romanticizes:
| Task Type | Cheap Backend Fit | Why |
|---|---|---|
| Docs cleanup | High | Low architectural risk and easy review |
| Test fixes | Medium | Useful if failures are local and reproducible |
| Dependency bumps | Medium | Needs strict CI, but cost savings can be real |
| Cross-module design | Low | This is where weaker reasoning gets expensive |
The trap is thinking cheap means free. Bad code review still costs time. Bad architecture still compounds. Bad edits still break deploys. A cheaper agent only helps if the review loop stays honest.
Measure quality like an engineering system
The evaluation I want is not “did it feel smart?” I want a boring spreadsheet attached to CI:
agent-task run --backend deepseek-v4-pro --label docs-cleanup
agent-task run --backend claude-opus --label tricky-refactor
agent-task report --group-by backend --metrics cost,retries,test-failures,reverted-lines
No, that exact CLI probably does not exist in your stack. The point is the shape. Backend choice should become measurable operational data, not a religious argument in Slack.
This is also where the topic connects to the broader open-model coding wave. The Kimi K2.6 story was about whether an open-weight model can be a serious default candidate for coding work. DeepClaude asks the next question: even if it is not the default, can a cheaper model become the workhorse behind the same harness?
My guess is yes, but unevenly.
The Real Lesson Is Model Routing
The agent stack is getting unbundled
DeepClaude is probably not the final form of anything. It might break. Anthropic might change assumptions. DeepSeek pricing might move. Better wrappers will show up. Some will be sketchy. Some will be genuinely useful.
But the direction feels hard to ignore. The coding agent stack is unbundling into pieces:
- the editor or terminal surface
- the agent harness
- tool permissions
- memory and repo context
- model routing
- verification
- cost controls
Once developers see those pieces separately, they stop accepting a single bundled price as the natural law of software development. That does not mean every team should chase the cheapest endpoint. It means every serious team will start asking which model should handle which kind of work.
That is why DeepClaude hit harder than a normal GitHub repo. It turned model arbitrage from a spreadsheet into something you can try in your terminal. And honestly? That is exactly how developer tools become real.